Voici le dernier post de ce blog, mais ce n'est pas la fin, juste assez de Blogger et de son interface. Elle a fait le taff pendant ces trois dernières années mais j'avoue m'en lasser et le blog en lui même n'a pas l'aspect que je voudrais. Donc je change.
Voila, donc si vous arrivez sur ce blog qu'il y a des choses qui vous intéressent, sachez qu'il poursuit sa vie ailleurs sur Wordpress a l'adresse suivante.
https://collonvillethomas.wordpress.com/
N’hésitez pas a y aller car l’intégralité des articles a été migré dedans et amélioré... donc peut être qu'il y a eut des corrections sur les articles que vous avez consulté ici même!
A bientôt donc.
lundi 4 mai 2020
mardi 28 avril 2020
Network, VM et IaC avec Vagrant
Introduction
Qui n'a jamais eut besoin de faire des tests dans un environnement sain et isolé du poste de développement? Personne je crois en tout cas si ce n'est pas le cas, vous y viendrais un jour, c'est sur car a un moment et si vous utiliser pas Docker, il va falloir confronter vos exe a l'environnement d’exécution de la Prod!Deux approches s'offrent généralement:
- bénéficier d'un environnement de test dédié, c'est a dire avoir une machine physique [bare-metal], pré-installé comme en prod sur laquelle il est possible de déployer votre application et exécuter des tests dessus. on se doute que cette approche est coûteuse en matériel et en maintenance (temps de nettoyage/ réinstallation des machine etc...)
- utiliser des machines virtuelles [machine-virtuelle].
La virtualisation
Cette deuxième approche [machine-virtuelle], que nous allons un peu plus détailler, offre de nombreux avantages car elle virtualise d'une part le matériel, donc pas de ressources physique a gérer mais elle permet de disposer d'environnement iso, réutilisable, ajustable et jetable rapidement. On pourra du coup évoquer bien sur le cas extrême de cette démarche par l'utilisation de Docker [Docker]. Pourtant il est important de ne pas confondre les deux outils et leurs objectifs respectifs. Le container isole un processus, une machine virtuelle isole un environnement. Cette dichotomie est importante car elle pousse a réfléchir a ce que l'on souhaite mettre en œuvre et pas faire un choix dogmatiquement.Ainsi pour en revenir aux machines virtuelles, leur intérêt est donc par l'abstraction de l’environnement d’exécution de permettre de disposer a la demande de cet environnement dans un état de configuration maîtrisé.
Jusque ici l'utilisation des machines passe généralement par le choix d'un hyperviseur, en gros une couche logicielle permettant d’allouer sur la stack physique de l'OS de la machine des ressources simulées. Cette démarche permet de créer des CPU virtuelle, de la mémoire virtuelle, du stockage virtuel ou même encore du réseau virtuel (nous reviendrons sur cette partie dans un autre article car c'est un sujet en soit).
L’inconvenant de l'utilisation d'un superviseur, c'est qu'il faut faire un choix. Selon le système d'exploitation qui est utiliser, on ne disposera pas des mêmes. De façon général, on notera malgré tout que l'offre est riche: qemu-KVM/libvirt [qemu], [virtualbox], hyper-v [hyper-v] ou encore vmware sont les plus connu. Pourtant et malgré des années d’existences, ces derniers n'offrent toujours pas d'API homogènes rendant leur utilisation au sein d'un même contexte compliqué car il faudra alors prendre en considération les spécificités de chacun d'eux.
Ainsi non seulement, souvent ces machines sont utilisé a la main mais lorsqu'il s'agit de gérer logiciellement le cycle de vie des VM et l'automatiser dans une démarche IaC (infrastructure as a code [IaC]), alors il faudra se limiter. Le quoi? l'IaC? Ce n'est pas important, nous y reviendrons!
Vagrant
Une solution est pourtant possible! Vagrant [vagrant]! Bon ce n'est pas une solution miracle, mais en terme de provisionning de machine virtuel, cet outil permet d'abstraire bon nombre de caracteristique propres aux hyperviseurs (en dehors de son choix propre mais cela reste variabilisable).Vagrant a surtout pour interet d'etre extremement simple d'emploi pour des actions basiques sur le cycle de vie d'une VM. En gros construire la VM, la lancer, l'arreter, ou encore la detruire se realise en juste quelques commandes. Bien sur qu'il permet d'ee faire plus mais globalement ca sera pour des utilisations en marge de celle utile au quotidien.
Ainsi pour realiser une VM, il va falloir en premier lieu la definir. Pour cela, on va realiser un fichier vagrantfile. Ce fichier s'appuie sur le language Ruby. sans etre un grand expert de Ruby, en fait ce fichier va etre essentiellement descriptif: Il va contenir un bloc "do" permettant de specifier la version vagrant utilisé. Dans ce bloc il va ensuite falloir decrire la VM en specifiant:
- son image de base qui sera issu d'une bibliotheque d'image hebergé par vagrant [vagrant-images].
- un nom qui servira de hostname,
- une config reseau selon 3 modes possibles:
- en port mapping permettant de router les paquet arrivant sur un port de la machine hote sur un port de la machine virtuelle
- avec un reseau privé, c'est a dire qu'un reseau virtuel sera construit dans laquelle la machine virtuelle aura une adressse IP. Ce reseau sera accessible alors par la machine hote et seulement celle ci (la machine host disposera alors d'un nouvelle interface avec une IP dans le reseau virtuel)
- avec un reseau publique, c'est a dire qu'une interface sera creer dans la machine virtuelle mais celle ci sera bridgé sur la machine hote dans le meme reseau que celle ci.
- un provider c'est a dire l'hyperviseur employé, et on pourra alors preciser le nombre de CPU virtuel et de memoire que l'on souhaite lui allouer.
Pour exemple, voici une allocation de VM possible:
1 2 3 4 5 6 7 8 9 | Vagrant.configure("2") do |config| config.vm.box = "generic/ubuntu1804" config.vm.hostname = "myvmtest" config.vm.network "public_network", :dev => "eno2", :mode => 'bridge', mac: "52:54:00:B2:14:8E", use_dhcp_assigned_default_route: true config.vm.provider "libvirt" do |vb| vb.memory = "1000" vb.cpus = "1" end end |
Pour lancer cette VM, rien de plus simple:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | $ vagrant up Bringing machine 'default' up with 'libvirt' provider... ==> default: Checking if box 'generic/ubuntu1804' is up to date... ==> default: Creating image (snapshot of base box volume). ==> default: Creating domain with the following settings... ==> default: -- Name: vagrant-template_default ==> default: -- Domain type: kvm ==> default: -- Cpus: 1 ==> default: ==> default: -- Feature: acpi ==> default: -- Feature: apic ==> default: -- Feature: pae ==> default: -- Memory: 1000M ==> default: -- Management MAC: ==> default: -- Loader: ==> default: -- Base box: generic/ubuntu1804 ==> default: -- Storage pool: default ==> default: -- Image: /var/lib/libvirt/images/vagrant-template_default.img (32G) ==> default: -- Volume Cache: default ==> default: -- Kernel: ==> default: -- Initrd: ==> default: -- Graphics Type: vnc ==> default: -- Graphics Port: -1 ==> default: -- Graphics IP: 127.0.0.1 ==> default: -- Graphics Password: Not defined ==> default: -- Video Type: cirrus ==> default: -- Video VRAM: 256 ==> default: -- Sound Type: ==> default: -- Keymap: en-us ==> default: -- TPM Path: ==> default: -- INPUT: type=mouse, bus=ps2 ==> default: Creating shared folders metadata... ==> default: Starting domain. ==> default: Waiting for domain to get an IP address... ==> default: Waiting for SSH to become available... default: default: Vagrant insecure key detected. Vagrant will automatically replace default: this with a newly generated keypair for better security. default: default: Inserting generated public key within guest... default: Removing insecure key from the guest if it's present... default: Key inserted! Disconnecting and reconnecting using new SSH key... ==> default: Setting hostname... ==> default: Configuring and enabling network interfaces... |
Cela va avoir pour consequence de provisionner la VM les ressources, faire l'allocation de l'IP via le DHCP et de fournir une interface en plus pour la maintenance.
Networking
Aisni, du coté host, on a un certain nombre d'interfaces reseaux "mysterieuse" qui ont ete crée, virbr0, vnet, macvtap0@eno2 on va revenir dessus:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | $ ip a 1: lo: [...] 2: eno2: <broadcast> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 04:92:26:1d:b2:e8 brd ff:ff:ff:ff:ff:ff inet 192.168.0.57/24 brd 192.168.0.255 scope global dynamic noprefixroute eno2 valid_lft 36031sec preferred_lft 36031sec 3: wlo1: [...] 41: virbr0: <broadcast> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 52:54:00:d7:c3:3c brd ff:ff:ff:ff:ff:ff inet 192.168.121.1/24 brd 192.168.121.255 scope global virbr0 valid_lft forever preferred_lft forever 42: virbr0-nic: <broadcast> mtu 1500 qdisc fq_codel master virbr0 state DOWN group default qlen 1000 link/ether 52:54:00:d7:c3:3c brd ff:ff:ff:ff:ff:ff 71: vnet0: <broadcast> mtu 1500 qdisc fq_codel master virbr0 state UNKNOWN group default qlen 1000 link/ether fe:54:00:51:d8:29 brd ff:ff:ff:ff:ff:ff 72: macvtap0@eno2: <broadcast> mtu 1500 qdisc fq_codel state UP group default qlen 500 link/ether 52:54:00:b2:14:8e brd ff:ff:ff:ff:ff:ff |
Mais dans la VM, on a que deux interfaces:
1 2 3 4 5 6 7 8 9 10 11 | $ vagrant ssh $ ip a 1: lo: [...] 2: eth0: <broadcast> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:51:d8:29 brd ff:ff:ff:ff:ff:ff inet 192.168.121.245/24 brd 192.168.121.255 scope global dynamic eth0 valid_lft 1943sec preferred_lft 1943sec 3: eth1: <broadcast> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 52:54:00:b2:14:8e brd ff:ff:ff:ff:ff:ff inet 192.168.0.110/24 brd 192.168.0.255 scope global dynamic eth1 valid_lft 41543sec preferred_lft 41543sec |
Pour expliquer un peu tout cela. Lors de la creation de la VM, vagrant va construire 2 interfaces, l'une pour la maintenance est utilisée lorsque l'on realise "vagrant ssh" (eth0) et l'autre est celle qu'on lui a demandé de creer dans le vagrantfile (eth0).
Du coté du host c'est un peu plus compliqué. On sait que l'interface que nous avons demandé de constuire a vagrant est une interface public mais par defaut, celle qu'il construit pour lui, ou celle de maintenance, est une interface privé.
On a donc deux approches differentes et forcement deux solutions (avant cela, je vous invite a aller relire l'article sur l'adressage [addressage], ca peut aider).
Reseau Privé
Pour les reseau privé, vagrant va constuire un network virtuel. Pour cela il va creer une interface associé present dans la VM (ici vnet0), de meme, il va creer une interface pour le host (ici virbr0-nic). Enfin, vagrant va construire un bridge [bridge] (ici virbr0) ou pont permettant d'alluer une ip au host, dans un plan d'addressage specifique.
C'est cette manipualtion qui va permettre la creation de ce reseau privé entre le host et la machien virtuelle permettant aux deux de communiquer ensemble. On peu le verifier en utilisant les commande suivante:
1 2 3 4 | $ brctl show
bridge name bridge id STP enabled interfaces
virbr0 8000.525400d7c33c yes virbr0-nic
vnet0
|
La commande brctl n'etant plus officiellement supporté sous certains OS, l'alternative est:
1 2 3 4 5 6 7 8 | $ ip link show type bridge_slave 42: virbr0-nic: <broadcast> mtu 1500 qdisc fq_codel master virbr0 state DOWN mode DEFAULT group default qlen 1000 link/ether 52:54:00:d7:c3:3c brd ff:ff:ff:ff:ff:ff 73: vnet0: <broadcast> mtu 1500 qdisc fq_codel master virbr0 state UNKNOWN mode DEFAULT group default qlen 1000 link/ether fe:54:00:20:a2:a1 brd ff:ff:ff:ff:ff:ff $ ip link show type bridge 41: virbr0: <broadcast> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:d7:c3:3c brd ff:ff:ff:ff:ff:ff |
Reseau Publique
Concernant l'interface publique, c'est plus simple car il existe deja une interface dans le reseau public, c'est eno2. Du coup au lieu de construire un bridge comme precedement, ici dans le host, vagrant va en construire une autre sorte, le macvtap, entre l'interface reseau de la VM identifié par son adresse mac (qui sera alors transposé sur le macvtap) et l'interface en02 de la machine host.
On peut le voir grace a la commande suivante:
1 2 3 | ip link show type macvtap
74: macvtap0@eno2: <broadcast> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 500
link/ether 52:54:00:b2:14:8e brd ff:ff:ff:ff:ff:ff
|
L'interet ici contrairement a l'interface public, c'est que l'adresse mac de la VM est visible depuis le reseau publique et donc qu'elle peut etre gerer par un service DHCP.
En resumé, tout cela donne le reseau suivant:

Il y aurait encore beaucoup a dire sur les aspects reseaux (le vlan par exemple, etc..) ou sur vagrant qui par le biais de plugin va permettre le provision automatique du contenu logiciel de la VM ainsi creer (via Ansible par exemple).
Ceci est un autre probleme que nous traiterons dans d'autres articles.
Références
- [bare-metal] https://www.ionos.fr/digitalguide/serveur/know-how/serveur-bare-metal-definition-et-structure/
- [machine-virtuelle] https://fr.wikipedia.org/wiki/Machine_virtuelle
- [Docker] https://www.docker.com/
- [qemu] https://www.qemu.org/
- [virtualbox] https://www.virtualbox.org/
- [hyper-v] https://docs.microsoft.com/fr-fr/virtualization/hyper-v-on-windows/about/
- [vmware] https://www.vmware.com/fr.html
- [IaC] https://www.lebigdata.fr/infrastructure-as-code-definition
- [vagrant] https://www.vagrantup.com
- [vagrant-images] https://app.vagrantup.com/boxes/search
- [ip-addr] https://memo-linux.com/ip-la-commande-linux-pour-gerer-son-interface-reseau/
- [addressage] https://un-est-tout-et-tout-est-un.blogspot.com/2020/04/networking-adressage.html
- [bridge] https://seravo.fi/2012/virtualized-bridged-networking-with-macvtap
samedi 25 avril 2020
Developpeur super-hero ou developpeur fou?
Ce n'est pas souvent que j’écris des billets d'humeur généralement deux ou trois par ans, je pense mais ce mois-ci, avec celui sur le Gain de Maturité, et bien ça en fera deux en un seul mois!.
Ce coup-ci ce n'est pas vraiment un billet positif que je vais écrire mais mais une forme de coup de gueule suite à une réflexion sur l’évolution (ou pas) des mentalités professionnelles dans le développement logiciel.
Nous avions un peu évoqué lorsque l'on traitait un peu plus de machine learning des origines de l'informatique. Ce qu'il faut surtout en retenir, c'est que l'informatique moderne a réellement explosé a la suite de la seconde guerre, l'apparition des transistor et bien sur des premiers langages de programmation.
Nous n'allons pas nous intéresser a cela dans ce billet mais aux humains qui ont "jalonnés" le monde de l'informatique jusqu’à aujourd'hui... Pas des humains en particulier mais au contraire ceux qui ont commencés par bidouiller dans leur garage dans les années 70, façonnés les premiers langages, outils logiciels (traitement de texte par exemple) ou jeux vidéos.
Dans la culture actuelle, cette époque est teintée d'une forme de belle époque ou seuls des boutonneux talentueux ont su comme lors de la conquête spatiale, poser un pied sur la lune et créer le monde de l'informatique moderne. On passera bien évidement sur tous ces gens aussi talentueux qui se sont planté dans leur entreprise a l’époque (bien sur on les a oublié...) mais ce qu'il en reste est cette image idyllique dans l'inconscient que tous ces gens étaient des super intello un peu autiste mais toujours sympa, que l'on comprenait pas vraiment, forcement harcelé a l’école, n'ayant pas de copine (je precise qu'en plus ce sont des garçons), et généralement seul ou avec une bande d'amis geek aussi... enfin vous voyez le tableau...
Cette image qui finalement place l'informaticien en mec bizarre mais quand même sympa et en plus vachement futé a donné quand même beaucoup envie a des gamins de se mettre devant un clavier. A l'image du personnage de Jerry Steiner dans Parker Lewis, effectivement, malgré tout, avec les moyen du bord, il fallait de la motivation a l’époque quand les programmes étaient encore enregistrer sur des cassettes audio (pour ceux ayant connu le MO5) et que pour en charger un il fallait parfois une bonne demi heure de lecture (tout ca pour charger quelques Ko en mémoire vive)
Les choses ont changé, s'il est certain que être informaticien est un métier complexe et nécessitant de nombreuses compétences, il ne s'agit plus (si ça a été vrai un jour d’ailleurs) de simplement connaître un langage de programmation, écrire du code qui marche et op balancer ça joyeusement en production en disant: Sur mon poste, ça marche!
Non le métier d’aujourd’hui, s'est professionnalisé et heureusement. Les outils du développeur ne sont plus des simples traitement de texte permettant de faire de la compilation du code, non ces outils intègrent des environnement complet, prés pour le développement sur de multiples langages en même temps, ayant des usages différents permettant des tests a des niveaux d'abstractions variables, facilitant l’intégration, améliorant la modélisation des systèmes, le monitoring et la collaboration.
A cela, s'ajoute écosystème dans lequel le développeur aura fait le choix de se spécialiser impliquant une compréhension des métiers associés a cet écosystème. Aujourd'hui, beaucoup d'application de gestion sont produite en Java mais si vous allez voir des applications embarqués, il y a peu de chance que Java soit un premier choix!
Ceci n'est encore que la composante technique du métier informaticien (et la plus plaisante a priori peut être mais...), car il ne faut pas oublier deux aspects: le contexte économique, c'est a dire les enjeux propre a l'entreprise et les processus qu'elle souhaite mettre en place pour faire de l'argent (oui forcement a un moment le salaire, il vient de quelque part) et enfin le caractère humain, c'est a dire la aussi être capable de communiquer, comprendre, expliquer et léguer.
A titre personnel je considère même ce dernier point comme étant le plus complexe a appréhender. Autant la technique, ce n'est que de la technique, par le travail, rien n'est incompréhensible ni inaccessible, la composante politique et économique, la comprendre permet de mieux saisir les enjeux, certes, mais notre impacts sur cet axe est faible. Par contre le caractère relationnel du métier, c'est un vrai défi qui au fils des années m’apparaît comme étant de plus en plus majeur a la réussite des projets! Car non seulement le travail qui est réalisé nécessite de la collaboration et du dialogue, de la pédagogie mais elle nécessite une vraie prise de conscience sur notre rapport au code, la manière de le réaliser, de le penser, de l’écrire.
Et c'est la que nous arrivons au cœur du problème de cette image du développeur super héros, elle nous dessers! Bien sur au delà des cliché s pseudo positif que cela entraîne, il en ressort en fait beaucoup de machisme et d'immaturité. (Je ne traiterai pas du sujet du machisme dans cette bataille mais c'est un sujet a part entière qui demande plus de recul que je n'ai en l’état actuel des choses...)
Cette immaturité, on la rencontre encore souvent chez ces profils restés dans cette vieille image. Souvent il s'agit de développeur vraiment très compétant sur leur sujet, qui peuvent être touche a tout techniquement mais qui s'en cognent joyeusement des principes du clean code... parce-que oui ce type de profil sait tellement bien faire son travail, que si son code n'est pas maintenable ou testé, ce n'est pas grave car il marche sur son poste ou que les autres ne sont pas assez bon pour comprendre son code et toute la subtilité qu'il a su y mettre quitte a revisiter les design pattern selon sa propre vision des choses.
Généralement, ces profils sont une plaie, leur code n'est souvent pas documenté (de toute facon la doc c'est pour les faibles) et les tests se limitent a des cas passant quand on a de la chance. Alors il est certain que dans les principes du clean code, la doc, on évite surtout le commentaire (on en reparlera quand on abordera le sujet clean code) car le code est sensé se suffire a lui même. Mais non la nous avons un super hero donc le code ne peut, que dis je, ne dois pas être simple! Pour ce type de développeur, il est forcement nécessaire de déployer des monstres de généricité pour résoudre tous les problèmes ... ba oui au cas ou quoi! Et la encore une fois on passe a coté de l'utilité même du code! Sans compter le caractère souvent immaintenable de ce type de code qui s'il faut le reconnaître est souvent très pointu, n'est jamais accessible a des débutants qui aurait pu espérer ne pas se sentir très null.
Le plus amusant c'est qu'avec le temps, ce genre de développeur prennent la grosse tête. Ils sont souvent vu comme fort et compétant (ba oui personne ne les comprennent!) et cela enrichi cette vision positive de super héro développeur qu'ils ont.
Et la c'est le drame, car leur compréhension de leur technique leur permettent de déroger aux règles fondamentales de la programmation et se permettent divers entorses (qu'il auraient critiqués en d'autres temps mais bon la ils sont fort donc ça va...) Et personnellement, j'en ai vu passer du code avec des "return null" en pagaille... DEPUIS QUAND NULL EST IL UNE VALEUR!!!!
Et c'est comme ça que après le passage de ces Heros, des équipes se tirent les cheveux à maintenir un code incompréhensible et non testé qui marche mais qui crash au moindre changement.... et forcement c'est la faute du développeur mainteneur, pas celui qui a littéralement (je me permet de le dire car vraiment c'est insupportable) chier dans la base code.
On peut encore trop en croiser de ce type de profil de développeur élevé dans cette culture du Super-hero qui n'ont pas pris la mesure de l’évolution du métier qui passe dans un projet, passe pour un génie et se barre en laissant derrière eux une ardoise que les suivant peineront a effacer mais devront assumer.
Voila du coup c’était mon coup de gueule. Et bien sur ce que j'ai décris au dessus c’était moi avant que je rencontre un autre moi en pire qui m'a fait prendre conscience que le code que nous écrivons, il n'est pas fait pour la machine, mais en réalité, il est fait pour nous.
Ce langage de programmation que nous utilisons et ce code que nous produisons, il faut etre lucide, ils ne sont que en fait qu'une sorte d'IHM pour le développeur et il ne sera pas seul a l'utiliser. D'autres passerons dessus et il doit être aussi accessible pour un autre que pour soit même et ce meme dans 5 ans!
Enfin voila tout ça, ça va être l'opportunité d'introduire au passage quelques sujets supplémentaires pour de prochains articles. Entre autre, je tacherai d'élargir ce blog à ces composantes qui sortent un peu du monde propre de l'informatique mais qui y ont une importance majeur pour que les projets se mènent aux mieux.
On tachera donc de parler un peu plus de Clean Code, et d'Egoless Programming, de CNV (Communication non violente) et comment elle peut nous aider a mieux travailler en équipe et aussi de regarder le code différemment et enfin on parlera aussi des biais cognitif, sujet passionnant qui nous emmènent souvent dans des travers de jugement qui peuvent nuire aux autres, a nous même et a la qualité de ce que l'on produit.
Ce coup-ci ce n'est pas vraiment un billet positif que je vais écrire mais mais une forme de coup de gueule suite à une réflexion sur l’évolution (ou pas) des mentalités professionnelles dans le développement logiciel.
Naissance d'un métier
Nous avions un peu évoqué lorsque l'on traitait un peu plus de machine learning des origines de l'informatique. Ce qu'il faut surtout en retenir, c'est que l'informatique moderne a réellement explosé a la suite de la seconde guerre, l'apparition des transistor et bien sur des premiers langages de programmation.
Nous n'allons pas nous intéresser a cela dans ce billet mais aux humains qui ont "jalonnés" le monde de l'informatique jusqu’à aujourd'hui... Pas des humains en particulier mais au contraire ceux qui ont commencés par bidouiller dans leur garage dans les années 70, façonnés les premiers langages, outils logiciels (traitement de texte par exemple) ou jeux vidéos.
Nostalgie
Dans la culture actuelle, cette époque est teintée d'une forme de belle époque ou seuls des boutonneux talentueux ont su comme lors de la conquête spatiale, poser un pied sur la lune et créer le monde de l'informatique moderne. On passera bien évidement sur tous ces gens aussi talentueux qui se sont planté dans leur entreprise a l’époque (bien sur on les a oublié...) mais ce qu'il en reste est cette image idyllique dans l'inconscient que tous ces gens étaient des super intello un peu autiste mais toujours sympa, que l'on comprenait pas vraiment, forcement harcelé a l’école, n'ayant pas de copine (je precise qu'en plus ce sont des garçons), et généralement seul ou avec une bande d'amis geek aussi... enfin vous voyez le tableau...
Cette image qui finalement place l'informaticien en mec bizarre mais quand même sympa et en plus vachement futé a donné quand même beaucoup envie a des gamins de se mettre devant un clavier. A l'image du personnage de Jerry Steiner dans Parker Lewis, effectivement, malgré tout, avec les moyen du bord, il fallait de la motivation a l’époque quand les programmes étaient encore enregistrer sur des cassettes audio (pour ceux ayant connu le MO5) et que pour en charger un il fallait parfois une bonne demi heure de lecture (tout ca pour charger quelques Ko en mémoire vive)
La vraie vie
Les choses ont changé, s'il est certain que être informaticien est un métier complexe et nécessitant de nombreuses compétences, il ne s'agit plus (si ça a été vrai un jour d’ailleurs) de simplement connaître un langage de programmation, écrire du code qui marche et op balancer ça joyeusement en production en disant: Sur mon poste, ça marche!
Non le métier d’aujourd’hui, s'est professionnalisé et heureusement. Les outils du développeur ne sont plus des simples traitement de texte permettant de faire de la compilation du code, non ces outils intègrent des environnement complet, prés pour le développement sur de multiples langages en même temps, ayant des usages différents permettant des tests a des niveaux d'abstractions variables, facilitant l’intégration, améliorant la modélisation des systèmes, le monitoring et la collaboration.
A cela, s'ajoute écosystème dans lequel le développeur aura fait le choix de se spécialiser impliquant une compréhension des métiers associés a cet écosystème. Aujourd'hui, beaucoup d'application de gestion sont produite en Java mais si vous allez voir des applications embarqués, il y a peu de chance que Java soit un premier choix!
Ceci n'est encore que la composante technique du métier informaticien (et la plus plaisante a priori peut être mais...), car il ne faut pas oublier deux aspects: le contexte économique, c'est a dire les enjeux propre a l'entreprise et les processus qu'elle souhaite mettre en place pour faire de l'argent (oui forcement a un moment le salaire, il vient de quelque part) et enfin le caractère humain, c'est a dire la aussi être capable de communiquer, comprendre, expliquer et léguer.
A titre personnel je considère même ce dernier point comme étant le plus complexe a appréhender. Autant la technique, ce n'est que de la technique, par le travail, rien n'est incompréhensible ni inaccessible, la composante politique et économique, la comprendre permet de mieux saisir les enjeux, certes, mais notre impacts sur cet axe est faible. Par contre le caractère relationnel du métier, c'est un vrai défi qui au fils des années m’apparaît comme étant de plus en plus majeur a la réussite des projets! Car non seulement le travail qui est réalisé nécessite de la collaboration et du dialogue, de la pédagogie mais elle nécessite une vraie prise de conscience sur notre rapport au code, la manière de le réaliser, de le penser, de l’écrire.
Les comportements toxiques
Et c'est la que nous arrivons au cœur du problème de cette image du développeur super héros, elle nous dessers! Bien sur au delà des cliché s pseudo positif que cela entraîne, il en ressort en fait beaucoup de machisme et d'immaturité. (Je ne traiterai pas du sujet du machisme dans cette bataille mais c'est un sujet a part entière qui demande plus de recul que je n'ai en l’état actuel des choses...)
Cette immaturité, on la rencontre encore souvent chez ces profils restés dans cette vieille image. Souvent il s'agit de développeur vraiment très compétant sur leur sujet, qui peuvent être touche a tout techniquement mais qui s'en cognent joyeusement des principes du clean code... parce-que oui ce type de profil sait tellement bien faire son travail, que si son code n'est pas maintenable ou testé, ce n'est pas grave car il marche sur son poste ou que les autres ne sont pas assez bon pour comprendre son code et toute la subtilité qu'il a su y mettre quitte a revisiter les design pattern selon sa propre vision des choses.
Généralement, ces profils sont une plaie, leur code n'est souvent pas documenté (de toute facon la doc c'est pour les faibles) et les tests se limitent a des cas passant quand on a de la chance. Alors il est certain que dans les principes du clean code, la doc, on évite surtout le commentaire (on en reparlera quand on abordera le sujet clean code) car le code est sensé se suffire a lui même. Mais non la nous avons un super hero donc le code ne peut, que dis je, ne dois pas être simple! Pour ce type de développeur, il est forcement nécessaire de déployer des monstres de généricité pour résoudre tous les problèmes ... ba oui au cas ou quoi! Et la encore une fois on passe a coté de l'utilité même du code! Sans compter le caractère souvent immaintenable de ce type de code qui s'il faut le reconnaître est souvent très pointu, n'est jamais accessible a des débutants qui aurait pu espérer ne pas se sentir très null.
Le plus amusant c'est qu'avec le temps, ce genre de développeur prennent la grosse tête. Ils sont souvent vu comme fort et compétant (ba oui personne ne les comprennent!) et cela enrichi cette vision positive de super héro développeur qu'ils ont.
Et la c'est le drame, car leur compréhension de leur technique leur permettent de déroger aux règles fondamentales de la programmation et se permettent divers entorses (qu'il auraient critiqués en d'autres temps mais bon la ils sont fort donc ça va...) Et personnellement, j'en ai vu passer du code avec des "return null" en pagaille... DEPUIS QUAND NULL EST IL UNE VALEUR!!!!
Et c'est comme ça que après le passage de ces Heros, des équipes se tirent les cheveux à maintenir un code incompréhensible et non testé qui marche mais qui crash au moindre changement.... et forcement c'est la faute du développeur mainteneur, pas celui qui a littéralement (je me permet de le dire car vraiment c'est insupportable) chier dans la base code.
On peut encore trop en croiser de ce type de profil de développeur élevé dans cette culture du Super-hero qui n'ont pas pris la mesure de l’évolution du métier qui passe dans un projet, passe pour un génie et se barre en laissant derrière eux une ardoise que les suivant peineront a effacer mais devront assumer.
Voila du coup c’était mon coup de gueule. Et bien sur ce que j'ai décris au dessus c’était moi avant que je rencontre un autre moi en pire qui m'a fait prendre conscience que le code que nous écrivons, il n'est pas fait pour la machine, mais en réalité, il est fait pour nous.
Ce langage de programmation que nous utilisons et ce code que nous produisons, il faut etre lucide, ils ne sont que en fait qu'une sorte d'IHM pour le développeur et il ne sera pas seul a l'utiliser. D'autres passerons dessus et il doit être aussi accessible pour un autre que pour soit même et ce meme dans 5 ans!
Enfin voila tout ça, ça va être l'opportunité d'introduire au passage quelques sujets supplémentaires pour de prochains articles. Entre autre, je tacherai d'élargir ce blog à ces composantes qui sortent un peu du monde propre de l'informatique mais qui y ont une importance majeur pour que les projets se mènent aux mieux.
On tachera donc de parler un peu plus de Clean Code, et d'Egoless Programming, de CNV (Communication non violente) et comment elle peut nous aider a mieux travailler en équipe et aussi de regarder le code différemment et enfin on parlera aussi des biais cognitif, sujet passionnant qui nous emmènent souvent dans des travers de jugement qui peuvent nuire aux autres, a nous même et a la qualité de ce que l'on produit.
mercredi 22 avril 2020
Maintenance Raid
On avait vu comment monter des disques en Raid [raid]. Mais je n'avais pas évoqué la question de comment reprendre un disque défaillant.
Data pas de panique, un disque peu très bien avoir eut un soucis de connexion et le raid l'a détecté et l'a donc placer en erreur.
Pour savoir si un disque est ko, il faut utiliser l'utilitaire mdadm:
Le récapitulatif qui vous sera fourni vous donnera alors l’état des disques faisant parti du Raid.
En suite une fois identifié le problème, et dans la mesure ou le disque est recupérable alors il faudra identifier le disque en question pour ensuite le réintroduire dans le raid.
Pour cela un simple!:
Puis pour réintroduire le disque:
(Si c'est le disque sdd1 qui était initialement dans le raid)
Alors le disque va etre resynchroniser (car peut être qu'il n'a pas ete mise a jour des dernieres infos.
Pour voir l’état de la resynhro, il suffit d'observer le fichier mdstat avec
Et la vous aurez votre raid de nouveau opérationnel.
[raid] https://un-est-tout-et-tout-est-un.blogspot.com/2020/03/montage-raid.html
[mdadm] https://doc.ubuntu-fr.org/raid_logiciel
Data pas de panique, un disque peu très bien avoir eut un soucis de connexion et le raid l'a détecté et l'a donc placer en erreur.
Identification
Pour savoir si un disque est ko, il faut utiliser l'utilitaire mdadm:
1 | $ mdadm --detail /dev/md0
|
Le récapitulatif qui vous sera fourni vous donnera alors l’état des disques faisant parti du Raid.
En suite une fois identifié le problème, et dans la mesure ou le disque est recupérable alors il faudra identifier le disque en question pour ensuite le réintroduire dans le raid.
Pour cela un simple!:
1 | $ fdisk -l
|
Réparation
Puis pour réintroduire le disque:
1 | $ mdadm --manage /dev/md0 --add /dev/sdd1
|
(Si c'est le disque sdd1 qui était initialement dans le raid)
Alors le disque va etre resynchroniser (car peut être qu'il n'a pas ete mise a jour des dernieres infos.
Pour voir l’état de la resynhro, il suffit d'observer le fichier mdstat avec
1 | $ watch cat /proc/mdstat
|
Et la vous aurez votre raid de nouveau opérationnel.
Références:
[raid] https://un-est-tout-et-tout-est-un.blogspot.com/2020/03/montage-raid.html
[mdadm] https://doc.ubuntu-fr.org/raid_logiciel
dimanche 19 avril 2020
Le gain en maturité
Un petit billet d'humeur aujourd'hui suite à un constat. Quand j'ai commencé ce blog, j'avais la résolution de retrouver un rythme. J'en avais rapidement parler dans [donc-ca] sans vraiment être rentré dans le détail ensuite a l'occasion d'un bilan [autobio], la j'ai expliqué un peu mon parcours et pourquoi j'avais décidé de tenir ce blog.
Sur le fond au delà des raisons personnelles, si l'on souhaite être pragmatique, tenir un blog ça permet en premier lieu de faire une veille techno réaliste. Comme je l'expliquais dans [veille], a mon sens on peut bien lire tout les articles que l'on veut ou tous les tutoriaux du monde, le monde de l'informatique est vaste et très hétérogène et retenir quelque chose d'une lecture au delà de quelques semaines permet au mieux de pouvoir dire, "oui j'ai vu ou entendu parler", mais clairement celui qui prêtent dire "oui je connais" est un menteur.
Sans revenir sur le contenu de cet article [veille], prendre la mesure d'un outils ou d'un concept en informatique, cela nécessite au moins de manipuler. Cela permet de se confronter (un peu) aux limites, aux écueils, aux trucs fun d'une techno mais cela permet aussi de mieux la situer dans son écosystème technique.
Par expérience, la encore, (et cela me relève de mon opinion et peut être de mon fonctionnement, se rassurer, consolider, se prouver etc...) a mon sens il faut aussi aller au delà et écrire un billet sur ce que l'on voit, cela permet de consolider et de garder une trace de ce que l'on a fait.... car il faut pas se leurrer: on oubli!
Oui on oubli! Aussi bon soit votre mémoire, elle a une limite et un temps d’accès ou un temps de recontextualisation (vous savez le truc que vous savez mais vous savez plus pourquoi comment ni comme ça s'y rattache...)
Et la encore, mettre noir sur blanc (ou 1 sur 0) permet de fixer les choses, de mieux mémoriser et cerise sur le gâteau, vérifier si notre vision de quelques a du sens! Je ne compte plus aujourd'hui les fois ou lors de la rédaction d'un article je me suis rendu compte d'une faille dans ma compréhension des choses. Et parfois cela a même pus complètement remettre en question l'article!
Aujourd'hui, après 3 ans de rédaction plus ou moins suivi et prés de 170 publiés j'ai découvert un denier point intéressant a la rédaction d'articles. Non cela n’améliore pas l'orthographe désolé ! (même si la capacité rédactionnelle est quand même notablement amélioré) non mais la rédaction de tous ces articles permet a terme d'avoir son parcours en perspective.
Je ne parle pas forcement de pouvoir utiliser cela comme un outil du genre CV même si ce la peut y trouver du sens (jusqu’à un certain point) mais de simplement permettre de regarder son parcours, ce que l'on a appris, les choix que l'on a fait (ces derniers étant contextualisable avec parfois peut être des besoins, d'autres par goût personnel) et aussi de voir son évolution sur les sujets.
Quand je relis certains de mes articles (car oui ça m'arrive pas de façon narcissique mais parce que parfois c'est utile de les utiliser comme aide mémoire) je me rend compte que autant parfois j'ai pu être pertinent sur certains sujet parfois pas du tout. Pour tout dire, je me suis même demandé parfois si je ne devais pas retirer certains de mes anciens articles car je les juge aujourd'hui insuffisant....
Bien sur je ne ferai pas ça, car en fait ces articles démontrent une évolution, si leur contenu n'est pas pertinent, leur présence au milieu des autres faits états des tentatives pour avancer et construire. Bien sur parfois c'est léger et parfois il y a des bêtises de dites mais c'est la aussi que l'on apprend et que l'on se rend compte justement que l'on avance!
Donc voila un autre point qui devrais donner envie d’écrire: le droit de se tromper, la possibilité de prendre du recul, la joie de se voir évoluer et de gagner en maturité!
[donc-ca] https://un-est-tout-et-tout-est-un.blogspot.com/2017/09/donc-ca.html
[veille] https://un-est-tout-et-tout-est-un.blogspot.com/search?q=veille
[autobio] https://un-est-tout-et-tout-est-un.blogspot.com/2018/09/100-un-peu-dautobio.html
Ecrire un blog
Sur le fond au delà des raisons personnelles, si l'on souhaite être pragmatique, tenir un blog ça permet en premier lieu de faire une veille techno réaliste. Comme je l'expliquais dans [veille], a mon sens on peut bien lire tout les articles que l'on veut ou tous les tutoriaux du monde, le monde de l'informatique est vaste et très hétérogène et retenir quelque chose d'une lecture au delà de quelques semaines permet au mieux de pouvoir dire, "oui j'ai vu ou entendu parler", mais clairement celui qui prêtent dire "oui je connais" est un menteur.
De la veille
Sans revenir sur le contenu de cet article [veille], prendre la mesure d'un outils ou d'un concept en informatique, cela nécessite au moins de manipuler. Cela permet de se confronter (un peu) aux limites, aux écueils, aux trucs fun d'une techno mais cela permet aussi de mieux la situer dans son écosystème technique.
Par expérience, la encore, (et cela me relève de mon opinion et peut être de mon fonctionnement, se rassurer, consolider, se prouver etc...) a mon sens il faut aussi aller au delà et écrire un billet sur ce que l'on voit, cela permet de consolider et de garder une trace de ce que l'on a fait.... car il faut pas se leurrer: on oubli!
Oui on oubli! Aussi bon soit votre mémoire, elle a une limite et un temps d’accès ou un temps de recontextualisation (vous savez le truc que vous savez mais vous savez plus pourquoi comment ni comme ça s'y rattache...)
Et la encore, mettre noir sur blanc (ou 1 sur 0) permet de fixer les choses, de mieux mémoriser et cerise sur le gâteau, vérifier si notre vision de quelques a du sens! Je ne compte plus aujourd'hui les fois ou lors de la rédaction d'un article je me suis rendu compte d'une faille dans ma compréhension des choses. Et parfois cela a même pus complètement remettre en question l'article!
Mais pas que
Aujourd'hui, après 3 ans de rédaction plus ou moins suivi et prés de 170 publiés j'ai découvert un denier point intéressant a la rédaction d'articles. Non cela n’améliore pas l'orthographe désolé ! (même si la capacité rédactionnelle est quand même notablement amélioré) non mais la rédaction de tous ces articles permet a terme d'avoir son parcours en perspective.
Je ne parle pas forcement de pouvoir utiliser cela comme un outil du genre CV même si ce la peut y trouver du sens (jusqu’à un certain point) mais de simplement permettre de regarder son parcours, ce que l'on a appris, les choix que l'on a fait (ces derniers étant contextualisable avec parfois peut être des besoins, d'autres par goût personnel) et aussi de voir son évolution sur les sujets.
Quand je relis certains de mes articles (car oui ça m'arrive pas de façon narcissique mais parce que parfois c'est utile de les utiliser comme aide mémoire) je me rend compte que autant parfois j'ai pu être pertinent sur certains sujet parfois pas du tout. Pour tout dire, je me suis même demandé parfois si je ne devais pas retirer certains de mes anciens articles car je les juge aujourd'hui insuffisant....
Bien sur je ne ferai pas ça, car en fait ces articles démontrent une évolution, si leur contenu n'est pas pertinent, leur présence au milieu des autres faits états des tentatives pour avancer et construire. Bien sur parfois c'est léger et parfois il y a des bêtises de dites mais c'est la aussi que l'on apprend et que l'on se rend compte justement que l'on avance!
Donc voila un autre point qui devrais donner envie d’écrire: le droit de se tromper, la possibilité de prendre du recul, la joie de se voir évoluer et de gagner en maturité!
Références
[donc-ca] https://un-est-tout-et-tout-est-un.blogspot.com/2017/09/donc-ca.html
[veille] https://un-est-tout-et-tout-est-un.blogspot.com/search?q=veille
[autobio] https://un-est-tout-et-tout-est-un.blogspot.com/2018/09/100-un-peu-dautobio.html
jeudi 16 avril 2020
Networking: adressage
1. Introduction
Souvent je me dis qu’avoir un article récapitulatif des principes sous-jacents aux outils réseaux ne serait pas un luxe car on est régulièrement confronté à manipuler des flux entre des VM ou des conteneurs et parfois avoir les bon outils et bonnes connaissances pour bidouiller c’est pas de trop, (et ceux ayant lu les articles sur Iptable seront de mon avis, je pense …) Surtout que par expérience on oublie vite! Pour avoir fait pas mal de réseau à une époque aujourd’hui j’ai un peu l’impression d’en avoir oublié la moitié.
Donc avec cet article, on va essayer de refaire un tour des concepts principaux du networking, une adresse, un masque, un réseau, un bridge, un dns ou dhcp, on va essayer de revoir un peu tout ça avec les outils permettant de les mettre en oeuvre.
Bon je ne garanti pas que ça se fera qu’en un seul article….
2. Concepts principaux
2.1. Réseau
Un réseau, déjà qu’est ce que c’est? C’est tout simplement un ensemble de machines interconnectées. Bon jusque la je ne prend personne en traite. Seulement pour que ces machine communique entres elles, il est nécessaire qu’elles puissent s’identifier, c’est la que va intervenir l’adressage.
Pour ceux à qui OSI parle, nous nous trouvons alors dans la couche 3 celle que l’on nomme (étrangement) la couche réseau. A partir d’ici on évoluera assez peu dans les couches supérieur qui correspondent aux couches protocoles de transport et qui sont plus d’ordre logiciel. Par contre dans les couches inférieurs, nous trouverons le support de l’interconnexion réseau: l’interface réseau (identifiable matériellement par une adresse mac, celle ci est propre à l’interface) qui représente matériellement ou virtuellement le point de connections de la machine avec le ou les réseaux. Dans ce réseau, alors l’interface sera identifié via une adresse qui lui sera assignée, entre autre une adresse IP.
Quoi deux adresses? pourquoi une adresse mac et une adresse IP? Il faut se dire que les deux types d’adresses ne servent pas à la même chose. La premier sert à identifier physiquement une interface et donc une machine, pas la localiser alors que l’IP (nous le verrons plus tard) permet aussi la localisation de le cette machine dans le réseau. D’autre part, pour une même interface, il n’est pas exclu que celle ci puisse être dans deux réseaux différents. Ainsi, elle aura deux IP mais toujours qu’une adresse mac. Nous verrons plus en détails cela par la suite.
De façon général donc un réseau cela va être un espace sur lequel seront connecté des machines portant une adresse mac et une ou plusieurs adresses IP

Mais pour que cela soit plus concret, on peut représenter cela avec un routeur qui aura la charge d’enregistrer les machines connectées sur le réseau et de leur permettre d’interagir entre elles (un switch pourra faire globalement le même taff, au broadcast prés…).

Si l’on peut faire une analogie, lorsque vous souhaitez envoyer un courrier à la poste, vous envoyez votre avec l’adresse du destinataire et la poste (ici le routeur) se charge de pousser ce message dans la bonne direction et au bon endroit.
Bon voila nous avons vu l’essentiel! non je rigole, enfin quoique car finalement il ne s’agit que de ça, du routage de ce que l’on appelle paquet.
2.2. IP
Mais non quand même pas c’est pas si simple. Car plein de question devrait arriver:
* comment les machines s’identifient dans le réseau ?
* comment sont définis les IP, qui les donne ?
* comment définir des réseaux différents sans prendre le risque qu’ils puissent se parler ?
* pourquoi les IP sont construites sur 4 digits?
* etc…
On va essayer de répondre à tout ça en entrant plus dans le détail de ce qu’est une IP.
On vient de le dire finalement, une IP c’est une adresse encodé sur 4 digits, en fait c’est ce que l’on appelle une IPv4. Vous en avez sûrement entendu parler, il existe aussi des IPv6, la différence est les nombre d’adresse que l’on va pouvoir construire avec les digits mais globalement c’est transposable. On gardera quand même nos explications sur IPv4, car nous allons le voir ça sera plus simple "visuellement".
Donc une IP (IPv4) c’est 4 digit allant de 0 à 255. Par exemple, 192.168.0.10 est une IPv4. De cette façon, on va pouvoir construire 4 milliards d’adresses… (ça fait beaucoup mais… en fait aujourd’hui ça pose problème: pc + serveurs + Iot etc… en fait on les a exploser d’où l’apparition de IPv6 mais c’est une autre histoire)
Par contre on s’est rendu compte que l’on ne pouvait pas considérer que l’on puisse adresse tout internet sur la base brute de ces 4 milliard d’adresses possibles. D’une part, à gérer cela aurait été trop gros et d’autre par, il est apparu important de pouvoir segmenter les réseaux, de façon à les isoler. Différentes topologie ont donc du être considéré: les petits réseaux qui finalement n’avait pas besoin de beaucoup d’adresse possible et les grands pour qui c’est l’inverse.
On a donc créer des classes de réseaux identifiables via du masquage d’adresse.
2.3. Masquage réseau
Le masquage consiste à définir un pattern permettant de contextualiser une adresse IP. En utilisant un masque, l’adresse fournira alors deux type d’information, celle identifiant la machine, et celle identifiant le plan d’adressage du réseau dans lequel cette machine se trouve.
Par exemple, considérons l’IP : 192.168.0.25. En l’état la seul chose que l’on puisse dire c’est qu’il n’existe d’un réseau et cette IP est associé à la machine numéro 192.168.0.25.
Pas contre l’utilisation d’un masque spécifiant par exemple 255.255.255.0 (/24). Nous permet de dire qu’en fait cette machine fait parti du réseau 192.168.0.0 et qu’elle est la machine numéro 25.
La notion de masque à été standardisé au travers des classes A,B,C,D et E… [classe-IP] Ici nous ne nous y intéresserons pas.
Le principe du masquage nous permet ici d’avoir un réseau restreint contenant que 255 machine possible. L’intérêt par contre est que ce plan d’adressage en 192.168.0.0 est réutilisable dans un autre réseau qui serait isolé et indépendant de celui-ci car aucune des machines ne pourrait se connaître et on pourrait alors avoir dans chacun de ces deux réseaux une machine portant la mémé adresse. Comme ci dessous.
Ici on a deux réseaux avec un plan d’adressage identique mais qui sont interconnectés via un troisième réseau qui lui les identifie dans un plan d’adressage diffèrent (on y viendra mais alors il faudra penser à utiliser des routeurs afin de permettre à toutes ces machines de parler entre elle, on verra cela lors du routage).

Un autre solution à la topologie précédente est d’utiliser un sous masque réseau sur la base d’un masque réseau plus large. Ainsi on crée des réseaux dans le plan d’adressage initial permettant d’avoir une décomposition logique et minimiser le nombre de routeurs à déployer

3. Exemple
C’est bien tout ça mais dans la vraie vie comme ça se présente? Pour faire simple, et visualiser cela depuis sa machine, deux outils peuvent être employé.
Le très célèbre ifconfig (ipconfig sous windows) [ifconfig] qui nous restituera l’ensemble des interfaces de notre machine avec les informations dont nous venons de parler:
IfConfig
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
$ ifconfig
eno2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.57 netmask 255.255.255.0 broadcast 192.168.0.255
ether 04:56:26:1d:b2:96 txqueuelen 1000 (Ethernet)
RX packets 8229590 bytes 7371495080 (7.3 GB)
RX errors 0 dropped 184 overruns 0 frame 0
TX packets 7627831 bytes 1670924458 (1.6 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Boucle locale)
RX packets 459205 bytes 108586619 (108.5 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 459205 bytes 108586619 (108.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlo1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.43 netmask 255.255.255.0 broadcast 192.168.0.255
ether 48:14:7f:86:2e:69 txqueuelen 1000 (Ethernet)
RX packets 148857 bytes 23021004 (23.0 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 48859 bytes 5284481 (5.2 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
On y retrouve l’interface filaire eno2 et l’interface wifi wlo1. A noter lo qui est ce que l’on appelle la loopback qui est en 127.0.0.1 qui permet à la machine de se parler à elle même sans préjuger du réseau dans lequel elle se trouve.
L’autre outil est plus récent que ifconfig il s’agit de ip [ip-tool], un outil générique pour la manipulation des concepts réseaux, nous reviendrons souvent dessus.
IfConfig
1
2
3
4
5
6
7
8
9
10
11
12
13
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eno2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 04:92:26:de:b2:e8 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.57/24 brd 192.168.0.255 scope global dynamic noprefixroute eno2
valid_lft 32728sec preferred_lft 32728sec
3: wlo1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 48:de:7f:09:2e:69 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.43/24 brd 192.168.0.255 scope global dynamic noprefixroute wlo1
valid_lft 37450sec preferred_lft 37450sec
Enfin , maintenant que nos machines sont identifiables dans le réseau, il va falloir définir comment leur donner ces adresses!
4. DHCP, passerelle et DNS
La ça va être le rôle du DHCP (Dynamic Host Configuration Protocole) [dhcp]. En effet, il est toujours possible d’allouer une adresse ip manuellement à une machine typiquement on ferai comme ceci:
Ip manuelle
1
$ sudo ip addr add 192.168.0.125 dev eno2
Mais honnêtement si votre parc de machine ou serveur comporte 200 équipements réseaux dont la plupart ont des interfaces réseaux redonnées, alors je vous souhaite bien du courage!
Non le plus simple est de déléguer ça à un gestionnaire d’adresse réseaux qu’est le DHCP. Ainsi lorsqu’une machine n’a pas d’IP, elle va aller en demander une en broadcastant une requête sur le réseaux. Le serveur DHCP va y répondre et lui allouer une ip (parmi celle disponible en fonction de l’adresse réseau, du masque et des adresses déjà allouées) mais aussi lui donner l’adresse de la passerelle par défaut et l’adresse du DNS.
Ou-la, qu’est ce que c’est que ça encore! Oui nous n’en avons pas encore parler mais une machine du réseaux, si elle souhaite parler à une autre machine du même réseau, alors pas de soucis, le routage des paquets est direct. Par contre si cette machine est en dehors du réseau alors, il faudra qu’elle s’adresse à la passerelle pour que celle ci puisse relayer les messages vers un réseau plus compétant dans la résolution de l’IP (qui lui même fera pareil le cas échéant)… il s’agit du même mécanisme que celui que nous avions évoqué dans l’article sur Iptable et le routage [iptable].
Ce qu’il faut retenir c’est qu’une passerelle c’est comme votre box internet, quand vous allez sur internet ça passe par elle (elle a donc une ip dans votre réseau) et quand les réponses reviennent, cela passe par une ip externe qu’elle expose de façon à être identifié dans le réseau externe.
De même un serveur DNS est un serveur chargé de résoudre les noms de domaine et de machine et vous les traduire en adresse IP pour que vous puissiez contacter la machine en question.

Ainsi par exemple, vous voulez accéder au site www.google.fr . Ceci est un nom de domaine, pas une ip, donc vous allez devoir vous adresser au serveur DNS que le serveur DHCP. Ce que vous avez du DNS c’est son adresse IP et celle ci est un autre réseau que vous. Vous allez don envoyer votre requête à la passerelle qui poussera la demande au DNS. Le DNS répondra alors à la passerelle qui vous retransmettra le message Comportant l’IP du site web de google. Pour l’interroger, rebelotte, la requête est envoyé à la passerelle (oui je doute que votre réseau local contienne les serveur de google) qui la renverra sur l’IP de chez google.
A noter, que l’IP de google est probablement d’une passerelle également et que ses flux sont envoyé en interne dans d’autre sous réseau dont on a pas connaissance.
5. Conclusion
Voila, nous avons vu l’essentiel du réseau, les IP, les masques, quelques notions de routage et de résolutions de nom. Maintenant nous allons pouvoir aborder des choses plus intéressants: les réseaux virtuels et les bridges
6. Références
- [iptable] https://un-est-tout-et-tout-est-un.blogspot.com/2019/10/reseau-iptables-routeur-logiciel.html
- [OSI] https://fr.wikipedia.org/wiki/Mod%C3%A8le_OSI
- [classe-IP] https://fr.wikipedia.org/wiki/Classe_d%27adresse_IP
- [ifconfig] https://wiki.debian.org/fr/NetworkConfiguration
- [ip-tool] https://memo-linux.com/ip-la-commande-linux-pour-gerer-son-interface-reseau/
- [dhcp] https://fr.wikipedia.org/wiki/Dynamic_Host_Configuration_Protocol
- [dns] https://fr.wikipedia.org/wiki/Domain_Name_System
samedi 4 avril 2020
Docker : Swarm
Introduction
Problématique Microservices
Dans le contexte des infrastructures microservices, docker [docker] est la reference! Jusqu’a maintenant nous avions surotut vu son utilisation dans le cadre du processus de developpement voir d’integration, mais nous ne sommes pas allé sur le terrain de la mise en production.Qu’est ce que je veux dire? Ce que je veux dire, c’est qu’une architecture microservice necessite forcement plusieurs micorservice et c’est pour cela d’ailleur que nous avons vite utilisé [docker-compose] afin de nous faciliter la vie en lancant l’ensemble de ces microservices ensemble, pour ainsi dire "orchestrer".
Pourtant docker-compose n’est pas suffisant, en effet celui ci nous permet de mettre en place une deployement cible de nos microservices mais ces derniers n’evolent alors que dans la machine dans laquelle docker-compose a ete invoqué!
Dans le cas ou nous souhaiterions deployer l’ensemble de nos microservice selon des regles specifique de deploiement, (par exemple les composants front ensemble, les back ensemble etc…) alors il nous faut d’une part etre capable de deploier dans un ensemble de machine de facon transparente mais en plus de pouvoir facilement administrer ce deploiement!
La solution a cette problematique c’est le sujet de cet article, docker-swarm [docker-swarm]
Architecture
Docker swarm [docker-swarm-concepts] est un outil d’orchestration inclu dans docker engine. Un Swarm est un ensemble machine contenant docker et fonctionnant en mode swarm Danse ce cluster, on trouvera alors un manager (ou n selon la redondance souhaité) et des worker (le manager pouvant aussi cumuler le rôle de worker).
Comme dans docker-compose, on déclare des services correspondant a un etat descriptif de la configuration souhaitée auprès du manager qui va produire des taches de déploiement dans les workers.
Fonctionnalités
Docker Swarm permet:- de gérer un cluster de nœud définit dans un réseau de machine potentiellement distribué et heterogene.
- de fournir une description du déploiement orienté service comme docker compose
- de scaler les instances pour ajouter de la redondance logique
- de faire du monitoring et de la réconciliation: en cas de crash, swarm sera capable de détecter les instances éventuellement manquante et se chargera de les redémarrer
- de faire des mise a jour a chaud pour realiser des modifications sur la configuration de déploiement comme des mise a jour applicative et docker se chargera de réconcilier l’état reel avec l’etat voulu.
- de loadbalancer la charge des flux sur les n instances (les replicas que nous verrons plus loin)
Creation du cluster swarm
Architecture cible

Dans notre archi, on va jouer avec 1 manager principal redondé une fois et 5 workers (incluant les 2 managers).
On va vouloir faire un server de fichier via http (avec [nginx]) dont les données de configuration sont partagées via un partage [nfs] global au cluster. Par contre dans notre exemple nous considererons que les données a exposer ne sont disponible que sur manager et node1.
Nos instances nginx devront donc se trouver sur l’une ou ces deux workers.
Process
Pour creer le swarm, on va suivre la doc! [create-swarm]
On va sur la machine qui sera le manager et on execute la commande:
1 | $docker swarm init --advertise-addr 192.168.0.60
|
On obtient une reponse de la forme:
1 | $docker swarm join --token SWMTKN-1- 192.168.0.60:2377
|
Cette commande il faudra aller l’exécuter sur chaque machine ou est installé docker-engine. Avec la commande suivante il est possible de verifier que les noeuds ont bien eté ajouté:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | $ docker info Client: Debug Mode: false Server: Containers: 5 Running: 0 Paused: 0 Stopped: 5 Images: 21 Server Version: 19.03.6 [...] Swarm: active NodeID: tntgi3hb72z9ly8rgir8p1j9p Is Manager: true ClusterID: wr0n081vcbdyxaabz40y3k3n8 Managers: 1 Nodes: 4 Default Address Pool: 10.0.0.0/8 SubnetSize: 24 Data Path Port: 4789 [...] |
Pour redonder le manager il faut s’ajouter dans cluster comme noeud manager secondaire pour rendre possible l’execution des commandes en local (le poste de dev en fait) et non devoir les executer sur le manger en remote.
Sur le poste de dev, on execute la commande d’ajout d’un noeud classique:
1 | $ docker swarm join --token SWMTKN-1-<token-value> 192.168.0.60:2377
|
Et sur la machine manager on realise une promotion a la machine de dev (dev etant le nom hostname de la machine):
1 | $docker node promote dev
|
Pour obtenir des informations sur les noeuds:
1 2 3 4 5 6 7 | $ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
tntgi3hb72z9ly8rgir8p1j9p * manager Ready Active Leader 19.03.6
xbaxr3icsfc08a3liv4dr3v7p node1 Ready Active 19.03.8
fyvyl153mrly3jz12xt0bblb3 node2 Ready Active 19.03.8
vgqfp4qxuguma7u11ghyw847i node3 Ready Active 19.03.8
s4h7oyar5tnothrwp0p6ukews * dev Ready Active Reachable 19.03.5
|
En preparation et pour respecter la typologie a venir, on va ajouter un label a nos noeuds [add-label]. Nous verons plus tard pourquoi et comment cela va impacter le deploiement.
1 2 | $docker node update --label-add http=active manager $docker node update --label-add http=active node1 |
Deploiement d’un service dans le swarm
Process
Pour deploier nos service nginx, on va definir un ficheir docker-compose un peu booster et integrant quelques specifications supplementaire [deploy-swarm].1 2 3 4 5 6 7 8 9 10 11 12 | tc-ngnix:
image: nginx:1.17.2-alpine
volumes:
- "/media/nfs_storage/tc-nginx/conf:/etc/nginx:ro"
- "/mnt/raid/data:/usr/share/nginx/html/data:ro"
ports:
- 80:80
deploy:
replicas: 2
placement:
constraints:
- "node.labels.http==active"
|
Ce fichier va s’appuyer sur une image nginx evidemement, declarer les points de montage de conf et de data et definir :
- le nombre de replicas c’est a dire le nombre d’instance souhaité du container
- la strategie de placement via une contrainte permetant de n’utiliser que les nodes sur lesquels on a mis le label http
1 | $docker stack deploy --compose-file docker-compose.yml http-services |
Pour consulter le service
1 2 3 | $ docker stack services http-services ID NAME MODE REPLICAS IMAGE PORTS d0g78u03joll tc-infra-base_tc-ngnix replicated 2/2 nginx:1.17.2-alpine *:80->80/tcp |
Nous dit que nous avons bien deployer nos instances. Pour savoir ou? nous allons demander directement a docker avec un docker ps sur le manager:
1 2 3 | $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e7e989c8b5f5 nginx:1.17.2-alpine "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp http-services_tc-ngnix.1.xjww2x4g3ic3fs0h156vxneg0 |
Il en manque un! mais non il est sur le node1:
1 2 3 | $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a1e06407c418 nginx:1.17.2-alpine "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp http-services_tc-ngnix.2.ej3w74okhms3ir3gufbnockz7 |
Le plus simpa avec ca du coup c’est que notre server est accessible que ce soit:
- http://node1
- http://manager
- http://dev
- http://node2
- http://node3
Point de vigilance
Je n’entre pas dans le detail mais sur certains points quelques interrogation peuvent etre soulevé, concernant le partage de la conf et des datas a nginx via un point de montage [nfs]. Ce n’est pas une solution ideale mais elle a le merite d’etre rapide et simple a mettre en oeuvre mais attention alors a la securité….Pour aller un peu plus loin…
Pour voir un exemple similaire avec quelques manip en plus genre la mise a jour a chaud ou le scaling horizontal aller voir cet article [swarm-fun]Ensuite si vous voulez entrer dans la partie monitoring de vos containeurs et service avec des outils comme Prometheus ou Grafana, vous pouvez consulter [swarm-monitoring]
References
- [docker-swarm-concepts] https://docs.docker.com/engine/swarm/key-concepts/
- [docker-swarm] https://docs.docker.com/engine/swarm/
- [create-swarm] https://docs.docker.com/engine/swarm/swarm-tutorial/create-swarm/
- [deploy-swarm] https://docs.docker.com/engine/swarm/stack-deploy/
- [swarm-mode] https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/#replicated-and-global-services
- [add-label] https://docs.docker.com/engine/reference/commandline/node_update/#add-label-metadata-to-a-node
- [docker] https://docs.docker.com/
- [docker-compose] https://docs.docker.com/compose/
- [nfs] https://doc.ubuntu-fr.org/nfs
- [nginx] https://www.nginx.com/
- [swarm-fun] https://dzone.com/articles/fun-with-docker-swarm?edition=334876&utm_source=Daily%20Digest&utm_medium=email&utm_campaign=Daily%20Digest%202017-11-15
- [swarm-monitoring] https://dzone.com/articles/monitoring-docker-swarm?edition=451233&utm_source=Daily%20Digest&utm_medium=email&utm_campaign=Daily%20Digest%202019-02-11
lundi 30 mars 2020
Montage Raid
Introduction
Aujourd'hui un article court! et qui va aussi me servir d'aide mémoire: RAID!Besoin
RAID? Oui RAID [ubuntu-raid], pas le produit anti mouche, mais la solution de résilience du stockage! Attention, ici on ne parle pas de base de données mais d'une solution permettant de gérer la sauvegarde de données en terme de disponibilité et d’intégrité en cas de panne! Il s'agit en fait d'une technique de gestion des données au niveau le plus bas possible, entre autre, au niveau des disques!Solutions
Ainsi Il va exister différents niveaux RAID, assurant différents types de gestions des disques, allant de RAID 0 a RAID 10:- RAID 0: il ne s'agit pas d'une configuration permettant d'assurer de la sauvegarde mais de pouvoir tirer le maximum des performances des disques (en distribuant les données). Cette config nécessite au moins 2 disques.
- RAID 1: avec deux disques au moins, cette configuration permet de dupliquer a l'identique les informations sur les disques comme s'il n'y en avait qu'un. Ainsi en cas de panne, la redondance permet de garantir les données. Coté performance, vous permettrez d’améliorer le nombre d’accès disque parallèle au meilleur taux de transfert (limité a la vitesse d’accès disque classique)
- RAID 5: le RAID 5 est une combinaison du RAID 0 et du RAID 1 et nécessite 3 disques au minimum permettant d’améliorer les perf et de se garantir de la perte d'un disque. au delà les données seront perdu.
- RAID 6: le RAID 6, c'est du RAID 5 mais avec une gestion permettant la perte acceptable de deux disques avant la perte irrémédiable de données. Cela nécessite donc 4 disques...
- RAID 10: Avec 4 disques, ce mode est une combinaison matricielle du RAID 1 sur n disque et du RAID 0 sur m cluster des disques RAID 1. Le RAID 1 a pour but de garantir l’intégrité des données alors que le RAID 0 se veut optimiser les performances.
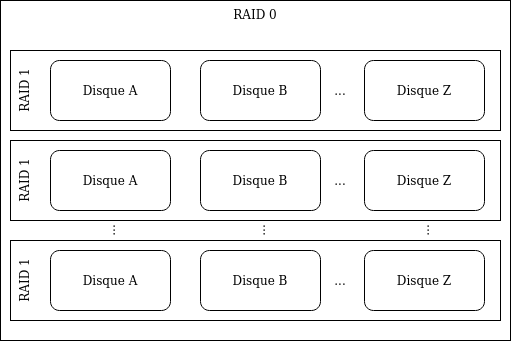
Exemple
Le cas du RAID 1
Identification des disques
1 | fdisk -l |
Creation du RAID 1
1 | mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1 |
Formatage du disque
1 | mkfs.ext4 /dev/md0 |
Montage du disque
Ajouter au fichier /etc/fstab la ligne suivante
/dev/md0 /mnt/raid ext4 defaults 0 1Pour ensuite monter le disque
1 | mount -a |
References
[ubuntu-raid] https://doc.ubuntu-fr.org/raid_logicieldimanche 29 mars 2020
Confinement, articles, boulots, tout ca tout ca....
Je n'ai pas beaucoup donné de signes de vie ce mois ci. Il faut dire que ce mois de mars a ete un peu spécial, je prévoyais d’écrire un peu plus. J'avais même pas mal de sujets sous le coude, mais tout ça a été perturbé : non seulement je devais normalement changer de mission début mars afin de rejoindre la cellule architecture de la boite dans laquelle je suis en mission, mais en plus de cela, la vague Coronavirus est arrivée!
Mon changement de mission a donc été reporté tout comme les missions dans lesquelles je devais intervenir. Ainsi en attendant, restant dans l'equipe initiale, il a fallu alors trouver de quoi s'occuper.
Bon de ce coté la, il y avait encore de quoi faire, surtout dans la thématique de soutien d’équipe (ce que l'on pourrait appeler DevOps aujourd'hui) et c'est justement sur ces sujets que les prochains articles vont s'appuyer (ba oui tant que c'est chaud).
Pourtant, pas d'articles! Ba oui en fait avec tout ca, il a fallu etre sur le pont! Car le coronavirus nous a un peu mis dehors de l'entreprise! Et il a fallu s'adapter au mode teletravail mais toutes les contraintes que cela peut appeler: déménagement, autorisations, VPN, organisation etc.. un grand pas en avant malgré tout!
Et finalement j'ai quand même changé d’équipe! donc forcement, de nouveaux sujets a aborder, des nouvelles contraintes de nouvelles réunions! Enfin bref, beaucoup de taff!
Du coup bien sur j'ai pris du retard, un bon mois même! Mais cela va se tasser, la routine commence a se remettre en place autant a la maison qu'au boulot! (pas dur c'est le même lieu du coup!) et on va aussi pouvoir se reallouer un peu de temps pour les articles!
Donc voila, je suis pas mort et prochainement, il devrait y avoir une petite série sur le DevOps qui devrait arriver! a bientôt donc!
Mon changement de mission a donc été reporté tout comme les missions dans lesquelles je devais intervenir. Ainsi en attendant, restant dans l'equipe initiale, il a fallu alors trouver de quoi s'occuper.
Bon de ce coté la, il y avait encore de quoi faire, surtout dans la thématique de soutien d’équipe (ce que l'on pourrait appeler DevOps aujourd'hui) et c'est justement sur ces sujets que les prochains articles vont s'appuyer (ba oui tant que c'est chaud).
Pourtant, pas d'articles! Ba oui en fait avec tout ca, il a fallu etre sur le pont! Car le coronavirus nous a un peu mis dehors de l'entreprise! Et il a fallu s'adapter au mode teletravail mais toutes les contraintes que cela peut appeler: déménagement, autorisations, VPN, organisation etc.. un grand pas en avant malgré tout!
Et finalement j'ai quand même changé d’équipe! donc forcement, de nouveaux sujets a aborder, des nouvelles contraintes de nouvelles réunions! Enfin bref, beaucoup de taff!
Du coup bien sur j'ai pris du retard, un bon mois même! Mais cela va se tasser, la routine commence a se remettre en place autant a la maison qu'au boulot! (pas dur c'est le même lieu du coup!) et on va aussi pouvoir se reallouer un peu de temps pour les articles!
Donc voila, je suis pas mort et prochainement, il devrait y avoir une petite série sur le DevOps qui devrait arriver! a bientôt donc!
dimanche 15 mars 2020
Samhain
Introduction
Samhain [samhain] est un outil de control d’intégrité pour les OS ou il importe de vérifier qu'une configuration n'est pas altéré dans le temps et qu'aucune intrusion n'a été réalisé.Pour ce faire l'outil va procéder au stockage de l'ensemble des empreintes des fichiers du système pour lesquels vous souhaitez assurer des garanties.
Pour cela il faudra configurer le fichier /etc/samhainrc avec l'ensemble des fichiers et répertoire sur lesquels opérer la surveillance.
Par défaut, cette configuration est largement déjà pertinente: surveillance des répertoires /etc, /var etc...
En pratique
Installation
Dans la pratique, Samhain est plutôt simple à utiliser:D'abord l'installer depuis le dépôt:
1 | $sudo apt-get install samhain
|
Ou depuis le targz sur le site officiel ce qui permet d avoir la derniere version:
1 | $wget https://la-samhna.de/samhain/samhain-current.tar.gz
|
on depackage:
1 2 3 4 | $gunzip /tmp/samhain-current.tar.gz $tar -xf /tmp/samhain-current.tar $gunzip samhain-4.4.1.tar.gz $tar -xf samhain-4.4.1.tar |
Et on build:
1 2 3 4 | $cd /tmp/samhain-4.4.1 $sudo ./configure $sudo make $sudo make install |
Et si vous souhaitez qu'un check soit fait lors des reboot:
1 | $sudo make install-boot
|
Initialisation
Enfin suite à l'installation, il faut initialiser la base de données (a faire qu'une seule fois):1 | $sudo samhain -t init
|
Utilisation
Ensuite dans son utilisation on procédé a des checks réguliers:1 | $sudo samhain -t check
|
Et si il est nécessaire de mettre a jour la base des empreintes (suite a l'installation d'une nouvelle application), on appelle la commande update
1 | $sudo samhain -t update
|
Configuration
Comme precisé dans l'introduction, la configuration (chapitre 5, [samhain]), de samhain se réalise dans le fichier /etc/samhainrcCette configuration se realise par l'application de regles sur des repertoires ou des fichiers (attention qui peuvent etre des repertoires sous unix tout est fichier)
Les relgles s'appliquent par des instructions precisées entre []. Ces instructions peuvent etre soit definies par l'utilisateur (ce que nous ne verons pas ici) soit utilisées via un pool d'instruction et regles pre-existantes.
Par exemple:
1 2 | [ReadOnly] dir = /some/directory |
La liste des instructions regles pre-existante ReadOnly, LogFiles, GrowingLogFiles, Attributes, IgnoreAll, IgnoreNone, etc... reponds deja globalement à l'ensemble des besoins pouvant être exprimés en terme de vérification d’intégrité.
Notification
Dernier point important, lors d'un check, même si celui ci est réalisé manuellement, il est important d'informer des anomalies éventuelles détectées mais aussi de les remonter auprès des systèmes d'informations en charge du monitoring.D'une part en tant que producteur de log et l'alerte, la configuration des niveau de criticité des messages se gère dans la section [EventSeverity] du même fichier de configuration.
De même, le type de flux d'alerte peut être configurer dans ce même fichier auprès de la même section permettant de produire ces alertes sous la forme de mail (chapitre 4.4), de flux syslog (chapitre 4.11) ou de messages (chapitre 7) a destination d'un serveur distant Samhain nommé Yule.
Le propos n'est pas de rentrer dans le détails ici de cette configuration mais syslog étant un type support standard pour la gestion de messages au travers d'un SI, il n'est déconnant de se tourner vers lui pour gérer ensuite agrégation du suivi et des alertes.
References
[samhain] https://la-samhna.de/samhain/
[simple] http://www.lestutosdenico.com/outils/samhain-multi-systeme-exploitation
[more-difficult] https://www.howtoforge.com/host-based-intrusion-detection-samhain
dimanche 23 février 2020
Spring-boot: RabbitMQ
On a jamais parler de Spring-boot [9], ça fait même assez longtemps que l’on a pas parler Java! Du coup comme nous sommes lancé dans les articles sur RabbitMQ et que ce message broker est assez courant dans ces écosystèmes, on va en profiter!
On va donc finir cette liste d’articles [2, 3] avec une mise en situation en réalisant une application client server implémentée avec Spring-boot (sur lequel nous reviendrons de façon plus général dans un autre article).

On va donc finir cette liste d’articles [2, 3] avec une mise en situation en réalisant une application client server implémentée avec Spring-boot (sur lequel nous reviendrons de façon plus général dans un autre article).
jeudi 20 février 2020
RabbitMQ : Configuration
Dans l’article précédent nous avions vu rapidement le fonctionnement de RabbitMQ [1]. Nous y avions vu comment le lancer dans un container Docker et de choisir quel type de binding et d’exchange utiliser selon nos besoins.
Par contre nous n’avions pas vu comment configurer de nouveaux exchanges, de nouvelles queues ou définir de nouveaux binding. Remédions à cela!
Pour réaliser une configuration, on peut utiliser l’interface web permettant de “jouer” et faire une config et des tests rapide. Par contre, il est évident que cela manque de reproductibilité. Il faut donc une approche et quelques outils.
Par contre nous n’avions pas vu comment configurer de nouveaux exchanges, de nouvelles queues ou définir de nouveaux binding. Remédions à cela!
Pour réaliser une configuration, on peut utiliser l’interface web permettant de “jouer” et faire une config et des tests rapide. Par contre, il est évident que cela manque de reproductibilité. Il faut donc une approche et quelques outils.
mardi 18 février 2020
RabbitMQ
Un message Broker
Qu’est ce que RabbitMQ? Il s’agit d’un message broker [4] qui à l'instar de JMS permet la réception et le dispatch de message au sein d’un système d’information.De façon logique, on va donc retrouver comme dans JMS une logique de files auxquelles les applications vont devoir s’abonner. La différence dans RabbitMQ est que la gestion des messages n’est pas limitée autour de l’utilisation de files ou de topic mais autour de files configurable [5] selon différentes configurations auxquelles vont être associées des clefs de routages permettant la gestion de la diffusion des messages.
samedi 8 février 2020
Postgres : Cluster Citus
Dans le logiciel, la sauvegarde des données métiers et applicatives est une problématique incontournable. Tôt où tard il faudra stocker et choisir une stratégie pérenne dans le temps afin de garantir que les données ne puissent être perdu tout en garantissant un accès facile et rapide à ces dernières
Pour cela deux techniques peuvent être mise en place, la mise en haute disponibilité [HD] qui permet de garantir que les données sont conservés intégré dans le temps et accessible malgré une panne éventuelle et le load balancing [LB] qui lui va permettre de garantir l’accessibilité dans un temps limité de ces données qu’elle qu’en soit le contexte d’exploitation
Pour cela deux techniques peuvent être mise en place, la mise en haute disponibilité [HD] qui permet de garantir que les données sont conservés intégré dans le temps et accessible malgré une panne éventuelle et le load balancing [LB] qui lui va permettre de garantir l’accessibilité dans un temps limité de ces données qu’elle qu’en soit le contexte d’exploitation
vendredi 31 janvier 2020
Docker, par ou commencer
Docker est une technologie que l'on croise de plus en plus aujourd'hui, on en a parler de nombreuses fois dans différents articles de ce blog [1].
Il est évident qu'il est aujourd'hui indispensable de monter en compétence sur le sujet car autant c'est un outil indispensable au déploiement en production mais c'est aussi un outil facilitant la vie du développeur évoluant dans un contexte DevOps [2].
Mais par ou commencer? Bien sur il y a la documentation en ligne [3] mais elle est conséquente et parfois il faut se poser dans un document prenant les choses dans l'ordre!
Du coup je vous propose le livre que j'ai lu a l’époque. Je ne dis pas qu'il s'agit de la référence mais il explique bien les fondamentaux, le socle de docker ainsi que les outils annexes comme docker-compose [4] et docker-swarm [5]. En prime différents exemple sont données permettant de bien se projeter dans l'utilisation de l'outil au quotidien.
Le voici donc et bonne lecture [6].

[2] https://un-est-tout-et-tout-est-un.blogspot.com/2019/01/lecture-devops-et-agilite.html
[3] https://docs.docker.com/
[4] https://docs.docker.com/compose/
[5] https://docs.docker.com/swarm/
[6] https://www.amazon.fr/dp/2100789708/ref=cm_sw_em_r_mt_dp_U_bVbnEb2F7NDDC
Il est évident qu'il est aujourd'hui indispensable de monter en compétence sur le sujet car autant c'est un outil indispensable au déploiement en production mais c'est aussi un outil facilitant la vie du développeur évoluant dans un contexte DevOps [2].
Mais par ou commencer? Bien sur il y a la documentation en ligne [3] mais elle est conséquente et parfois il faut se poser dans un document prenant les choses dans l'ordre!
Du coup je vous propose le livre que j'ai lu a l’époque. Je ne dis pas qu'il s'agit de la référence mais il explique bien les fondamentaux, le socle de docker ainsi que les outils annexes comme docker-compose [4] et docker-swarm [5]. En prime différents exemple sont données permettant de bien se projeter dans l'utilisation de l'outil au quotidien.
Le voici donc et bonne lecture [6].
Références:
[1] https://un-est-tout-et-tout-est-un.blogspot.com/search/label/Docker[2] https://un-est-tout-et-tout-est-un.blogspot.com/2019/01/lecture-devops-et-agilite.html
[3] https://docs.docker.com/
[4] https://docs.docker.com/compose/
[5] https://docs.docker.com/swarm/
[6] https://www.amazon.fr/dp/2100789708/ref=cm_sw_em_r_mt_dp_U_bVbnEb2F7NDDC
mercredi 15 janvier 2020
Evolution Java 10
Java évolue vite ! on avait vu dans un article Java 9 en novembre 2017. Cette version venait à peine de sortir! Avec ses nouveauté et ses modules mais c'était il a 3 ans déjà !
Ainsi si les précédentes versions de Java sortaient chaque fois avec plusieurs années d'écarts (embarquant du coup un contenu conséquent), le changement de politique de release d’Oracle consistant à sortir des versions plus régulièrement (tous les 6 mois à un an), à provoquer des contenus beaucoup moins complexe à appréhender.
Pourtant aujourd’hui on parle de java 14 pour février prochain! Il est donc temps de refaire un petit topo des nouveautés sorties depuis!
Ainsi si les précédentes versions de Java sortaient chaque fois avec plusieurs années d'écarts (embarquant du coup un contenu conséquent), le changement de politique de release d’Oracle consistant à sortir des versions plus régulièrement (tous les 6 mois à un an), à provoquer des contenus beaucoup moins complexe à appréhender.
Pourtant aujourd’hui on parle de java 14 pour février prochain! Il est donc temps de refaire un petit topo des nouveautés sorties depuis!
jeudi 9 janvier 2020
Faut il adopter Lombok?
Introduction
Lombok, qui ne connaît pas cet outil? Fallait il vraiment le présenter? Probablement que non car aujourd’hui, il n’existe plus beaucoup de projet java se faisant sans lui !
Mais pourquoi fait il ainsi l’unanimité parmi les développeurs et est ce vraiment une bonne idée de l’utiliser ou du moins qu’est ce que cela nous coûte de le faire?
Dans cet article, après avoir présenté et passer en revue les utilisations courantes de cet outil, nous essayerons d’en voir les limites si elles existent
Génération
Lombok est un outil d’aide au développeur permettant de compléter un code existant de façon transparente via des annotations. Cette action se réalise de façon caché à la compilation via un processeur d'annotation qui va alors générer le code manquant.Par exemple
Voici une classe Livre classique:
public class Livre { private String name; public Livre(String name) { this.name = name; } public String getName() { return this.name; } public void setName(String name) { this.name=name; } @Override public String toString() { return "Livre(name="+this.name+")"; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Livre livre = (Livre) o; return name.equals(livre.name); } @Override public int hashCode() { return Objects.hash(name); } }
Inscription à :
Articles (Atom)