Nous avons vu dans un précédent article les formes normales de SGBD-R. Mais au delà de définir les relations de notre base de données, il faut encore être capable de la manipuler, c’est a dire :
- consulter les données
- insérer des données
- supprimer des données
- mettre à jour les données
Pour cela, il faut étudier l’algèbre relationnelle. Inutile de rentrer dans des détails mathématiques, l’important est de considérer que l'algèbre relationnelle manipule des relations à l’aide d'opérateur unaire et binaire.
Nous avons en premier lieu des opérateurs ensemblistes qui vont nous permettre des opérations classique telles que l’union, l’intersection, la différence ou encore le produit cartésien et d’autres relationnelles comme le renommage, la sélection, la projection, la jointure et la division.
Union, intersection et différence
Les trois opérations d’union, d’intersection et de différence n’ont rien de particulier par rapport à la connaissance intuitive que nous avons de ces opérations a ceci prêt qu’il faut que les relations mises en œuvre aient les mêmes schémas:Ainsi considérons les relations A et B suivantes:
A
|
Nom
|
Prenom
|
Truc
|
Paul
| |
Machin
|
Pierre
|
B
|
Nom
|
Prenom
|
Schmurtz
|
Jacques
| |
Machin
|
Pierre
|
En sql:
Ainsi on aura:CREATE TABLE "A"(Nom varchar(40) NOT NULL,Prenom varchar(40) NOT NULL);
CREATE TABLE "B"(Nom varchar(40) NOT NULL,Prenom varchar(40) NOT NULL);
INSERT INTO "A" (Nom, Prenom) VALUES ('Truc', 'Paul');INSERT INTO "A" (Nom, Prenom) VALUES ('Machin','Pierre');INSERT INTO "B" VALUES ('Schmurtz','Jacques');INSERT INTO "B" VALUES ('Machin','Pierre');
select * from "A" UNION select * FROM "B";
A U B
|
Nom
|
Prenom
|
Truc
|
Paul
| |
Machin
|
Pierre
| |
Schmurtz
|
Jacques
|
select * from "A" INTERSECT select * FROM "B";
A inter B
|
Nom
|
Prenom
|
Machin
|
Pierre
|
select * from "A" EXCEPT select * FROM "B";
A - B
|
Nom
|
Prenom
|
Truc
|
Paul
|
select * from "B" EXCEPT select * FROM "A";
B - A
|
Nom
|
Prenom
|
Schmurtz
|
Jacques
|
Produit Cartésien
Le produit cartésien de deux relations est la concaténation des attributs des deux relations en une seule et unique relation. L’ensemble des enregistrements est alors la combinatoire des enregistrements des deux relations d’origines.CREATE TABLE "A"(val1 integer NOT NULL,val2 integer NOT NULL);INSERT INTO "A" (val1, val2) VALUES (1, 2);INSERT INTO "A" (val1, val2) VALUES (3, 4);
A
|
Val1
|
Val2
|
1
|
2
| |
3
|
4
|
CREATE TABLE "B"(str1 varchar(40) NOT NULL,str2 varchar(40) NOT NULL);INSERT INTO "B" (str1, str2) VALUES ('a', 'b');INSERT INTO "B" (str1, str2) VALUES ('c', 'd');
B
|
Str1
|
Str2
|
a
|
b
| |
c
|
d
|
select * from "A", "B" ;
A x B
|
Val1
|
Val2
|
Str1
|
Str2
|
1
|
2
|
a
|
b
| |
3
|
4
|
c
|
d
| |
1
|
2
|
c
|
d
| |
3
|
4
|
a
|
b
|
Renommage
Le renommage consiste en la modification du nom d’un attribut (dont l’objectif est d’effectuer plus facilement une autre opération) Le mot clef a employer en SQL est ASselect val1 AS newVal from "A";
A
|
newVal
|
1
| |
3
|
Sélection
La sélection est l'opération permettant de récupérer des données dans une relation. La sélection est fondamentale car elle permet d’extraire des données selon des critères ou des restrictions sur les attributs. Si l’on considère la relation A x B précédemment présentée,La section des enregistrements tels que Val1>2 nous donne la relation:
select * from "A", "B" where val1 > 2 ;
A x B >2
|
Val1
|
Val2
|
Str1
|
Str2
|
3
|
4
|
c
|
d
| |
3
|
4
|
a
|
b
|
Projection
La projection consiste a opérer une restriction sur un ou plusieurs attributs d’une relation. Par exemple , la projection de la relation A selon l’attribut val1 nous donnera:select val1 from "A";
A pi val1
|
val1
|
1
| |
3
|
Division
La division, n’est pas forcément très intuitive [2]. En algèbre relationnelle, celle ci consiste a considérer une nouvelle relation C dont les attributs sont la différence des attributs de la relation A moins la relation B.Ensuite pour construire le contenu de cette nouvelle relation C, on y insère le contenu pour lequel les deux relations initiales sont égales (sur le champs des attributs restant). Le contenu de C est la liste des éléments (d'attributs issus de la différence) pour lesquels il y a une complète superposition des autres attributs de A par B.
Ainsi formellement l'opération de division, B DIVIDE A, se définit:


{kind=link}

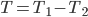
Dans les faits, il n’existe pas d'opérateur SQL implémentant l’operation “DIVIDE”. il nous faut alors décomposer l'opération pour en obtenir une vraie division. Il en existe plusieurs approches [4] et je vous propose d’en découvrir la plus “simple”.
Considérons alors un exemple (un autre vous est proposé ici [3]) avec des clients et des produits. L'opération de la division est équivalente à poser la question suivantes “qui des clients a acheté l’ensemble des produits de produit?”
Ajoutons les produits epad, asis, windause et définissons des clients les ayants achetés thomas, kevin et paul.
CREATE TABLE "Client"(nom varchar(40) NOT NULL,produit varchar(40) NOT NULL);CREATE TABLE "Produit"(produit varchar(40) NOT NULL);
INSERT INTO "Produit" VALUES ('epad');INSERT INTO "Produit" VALUES ('asis');INSERT INTO "Produit" VALUES ('windause');select * from "Produit";
Produit
|
produit
|
epad
| |
asis
| |
windause
|
INSERT INTO "Client" VALUES ('thomas','epad');INSERT INTO "Client" VALUES ('thomas','asis');INSERT INTO "Client" VALUES ('kevin','windause');INSERT INTO "Client" VALUES ('kevin','asis');INSERT INTO "Client" VALUES ('paul','asis');
select * from "Client" ;
Client
|
nom
|
produit
|
thomas
|
epad
| |
thomas
|
asis
| |
kevin
|
windause
| |
kevin
|
asis
| |
paul
|
asis
|
Pour répondre donc à la question et réaliser l’opération de la division, Joe CELKO a proposé de prendre le problème à l’envers, c’est à dire qu’au lieu de chercher les clients qui ont acheté tous les types de produits (nécessitant de devoir les compter, supprimer les doublons etc…), il propose de chercher les clients pour lesquels il n’existe pas de produit qui n’est pas possédé par le client. Il s’agit d’une double négation ce qui simplifie l'écriture de la requête qui contient malgré tout trois requêtes imbriquées qui ressemblera donc à ceci:
SELECT DISTINCT nomFROM "Client" AS C1WHERE NOT EXISTS(SELECT *FROM "Produit" pWHERE NOT EXISTS(SELECT *FROM "Client" AS C2WHERE C1.nom = C2.nomAND (C2.produit = p.produit)))
Client / Produit
|
nom
|
thomas
|
Pour les plus motivés à découvrir d’autres manières de faire, voici un article dédié à cette question [4].
Voici la première partie traitant de l’algèbre relationnelle, nous viendrons a une seconde qui s’intéressera aux jointures.
Références:
[2] https://www.google.fr/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0ahUKEwiaivuwvaDZAhUCSBQKHWpXDd4QFgguMAE&url=http%3A%2F%2Fwww.i3s.unice.fr%2F~edemaria%2Fcours%2Fc3.pdf&usg=AOvVaw05kk_PL5IdXIxKsT1WdRlm
[4] http://sqlpro.developpez.com/cours/divrelationnelle
Aucun commentaire:
Enregistrer un commentaire