Nous voici aujourd'hui sur un sujet JEE très classique qu'est JMS.
JMS pour Java Messaging System est un MOM (Message Oriented Middleware), c'est à dire un support intermédiaire (Middleware) pour l'échange de messages entre différents systèmes d'informations et/ou entres différentes couches applicatives. JMS se positionne donc comme solution technique pour des architectures spécifiques telles que celles que nous avons déjà vu dans l'article précédent sur les architectures types [1] en fournissant des solution de couplage faible entre les composants, des échanges de messages asynchrones (positionnable en synchrone mais cela enlève beaucoup d'intérêt a JMS), d'être scalable (c'est à dire qu'on l'on peut facilement ajouter des composants à l'ensemble des composant déjà présent dans le système sans perturbation notable) et sécurisé.
Pour permettre la mise en relation de ces composants de façon homogènes, JMS repose sur différents modes de communications orientées autour des concepts de queue (Queue) ou de sujet (Topic) [10]. Ces deux approches apportent leur propres paradigmes afin de répondre à des besoins soit d'échanges point à point, soit d'échange sous la forme de liste de diffusion.
L'intérêt de JMS est de définir un contexte où l'information est au centre des préoccupations et non les émetteurs ou les receveurs qui n'auront pas à s'acquitter de leur présence ou non sur le réseau et n'auront pas non plus en charge d'acquitter les messages (a moins que cela ne soit prévu via un autre flux).
lundi 30 avril 2018
jeudi 26 avril 2018
CMMI : DAR
Un nouveau projet s’offre à vous? Comment vous y prenez vous? Que faites vous?
Bien sur la première réaction est forcément de démarrer sur l’initialisation d’un processus de développement: analyse du besoin, modélisation, conception, etc. Seulement voilà, vous avez bien saisi ce que le client attend du logiciel qu’il vous a commandé mais comment allez vous y répondre? Quels sont les solutions technologiques qu’il va falloir employer? Quel langage de programmation allez vous utiliser? quelle architecture allez vous mettre en place?
Bien sûr cela peut sembler être du ressort de la phase de conception et que beaucoup des réponses vont naturellement se trouver directement lors de la phase d’analyse et de modélisation. Seulement voilà, un choix, ca se justifie, simplement car le client doit être convaincu que les choix techniques qui sont fait sont les bons mais aussi que ces choix vont trouver un optimal en terme de coût. De plus, généralement, avant même de réaliser quoique ce soit avec une équipe, une intégration continu et tout l’outillage qui va bien, il faudra répondre à un appel d’offre [3] où il faudra élaborer un dossier répondant le mieux possible aux besoins du clients dans un ordre de prix satisfaisant et concurrentiel.
Dans la gestion d’entreprise, la gestion de projet et la certification, nous connaissons tous la norme ISO et sa série des normes 9000 dont la plus connu est la norme 9001 gage de qualité [1]. Parallèlement à cela, dans le monde IT, un modèle de référence appelé CMMI [2, 4, 5] (Capability Maturity Model Integration) a été proposé afin de gérer au mieux les activités d’entreprises dédiés au monde de l'ingénierie logiciel.
CMMI permet de gérer plus efficacement les processus d’entreprise et de développement en fournissant un ensemble un ensemble de règles et de bonnes pratiques. Le but n’est pas de traité CMMI ici, ce sujet étant vaste on y dédiera quelques futurs articles, cependant dans la problématique qui nous intéresse de réaliser objectivement des choix techniques, l’approche propose de nous appuyer sur le DAR.
Faisant partie de CMMI, le DAR où Decision Analysis and Resolution est un processus d’analyse comparative de stratégies dont le propos est de fournir une aide à la décision par la mise en perspective de critères de différenciation.
L’utilisation du DAR a pour objectif de construire une réflexion autour des solutions envisageables d’un problème donné afin de faciliter le choix de l’une d’entre elles. Pour cela, il propose un processus guidant l’analyse afin d’en extraire des critères communs, comparables, et pondérés selon leur importances qui mis en relation permettent de dégager une tendance vers les solutions les plus pertinentes.

Ainsi la mise en oeuvre d’un DAR consiste en:
A noter que si les critères n’imposent d'être numérique, il est préférable de les manipuler comme tel le plus souvent possible afin de faciliter la compilation des “notes” des différentes alternatives et faciliter les comparaisons (chose plus difficile à mener si les critères sont des espace numérique tel que [faible, bon, fort])
De façon générale, les méthodes d’évaluations peuvent être choisi parmi celles déjà employé par les communautés. Basiquement, des tests peuvent être employés en réalisant par exemple un POC (Proof of concept) mais il est aussi possible de réaliser de la modélisation et de la simulation où de manière encore plus pousser, réaliser des études statistiques (selon des approches fréquentiste ou bayésienne, mais nous y reviendrons dans un prochain article)
[2] https://fr.wikipedia.org/wiki/Capability_Maturity_Model_Integration
[3] https://bee4win.com/lavant-vente-cest-quoi/
[4] https://msdn.microsoft.com/fr-fr/library/ee461556.aspx
[5] https://cmmiinstitute.com/cmmi
Bien sur la première réaction est forcément de démarrer sur l’initialisation d’un processus de développement: analyse du besoin, modélisation, conception, etc. Seulement voilà, vous avez bien saisi ce que le client attend du logiciel qu’il vous a commandé mais comment allez vous y répondre? Quels sont les solutions technologiques qu’il va falloir employer? Quel langage de programmation allez vous utiliser? quelle architecture allez vous mettre en place?
Bien sûr cela peut sembler être du ressort de la phase de conception et que beaucoup des réponses vont naturellement se trouver directement lors de la phase d’analyse et de modélisation. Seulement voilà, un choix, ca se justifie, simplement car le client doit être convaincu que les choix techniques qui sont fait sont les bons mais aussi que ces choix vont trouver un optimal en terme de coût. De plus, généralement, avant même de réaliser quoique ce soit avec une équipe, une intégration continu et tout l’outillage qui va bien, il faudra répondre à un appel d’offre [3] où il faudra élaborer un dossier répondant le mieux possible aux besoins du clients dans un ordre de prix satisfaisant et concurrentiel.
Dans la gestion d’entreprise, la gestion de projet et la certification, nous connaissons tous la norme ISO et sa série des normes 9000 dont la plus connu est la norme 9001 gage de qualité [1]. Parallèlement à cela, dans le monde IT, un modèle de référence appelé CMMI [2, 4, 5] (Capability Maturity Model Integration) a été proposé afin de gérer au mieux les activités d’entreprises dédiés au monde de l'ingénierie logiciel.
CMMI permet de gérer plus efficacement les processus d’entreprise et de développement en fournissant un ensemble un ensemble de règles et de bonnes pratiques. Le but n’est pas de traité CMMI ici, ce sujet étant vaste on y dédiera quelques futurs articles, cependant dans la problématique qui nous intéresse de réaliser objectivement des choix techniques, l’approche propose de nous appuyer sur le DAR.
Faisant partie de CMMI, le DAR où Decision Analysis and Resolution est un processus d’analyse comparative de stratégies dont le propos est de fournir une aide à la décision par la mise en perspective de critères de différenciation.
L’utilisation du DAR a pour objectif de construire une réflexion autour des solutions envisageables d’un problème donné afin de faciliter le choix de l’une d’entre elles. Pour cela, il propose un processus guidant l’analyse afin d’en extraire des critères communs, comparables, et pondérés selon leur importances qui mis en relation permettent de dégager une tendance vers les solutions les plus pertinentes.
Ainsi la mise en oeuvre d’un DAR consiste en:
Guidelines
La définition du processus d'évaluation permettant de donner un fil conducteur à l’instanciation du DAR. Cela passe par la mise en oeuvre de recommandations pour avoir une approche la plus objective, la nécessité de commenter chacun des critères choisis et de justifier les notes données à chaque alternatives.Bien que coûteux en mise en place, la rationalisation de la prise de décision à l’avantage d’augmenter les chances de converger vers la solution la plus pertinente en la définition de critères objectifs et globaux.Critères
la définition de critères d’évaluation des différentes alternatives (en terme de risque, de facilité d’utilisation, de pérennité, etc...) Ces critères se définissent selon les caractéristiques formelles des alternatives étudiées mais peuvent également faire apparaître des axes moins objectifs comme son côté fun. Ainsi, dans le monde du génie logiciel, le choix d’une technologie pourra être dirigé par la capacité de l'équipe à la maintenir, sa courbe d’apprentissage, les environnements de test disponibles, etc… et même donc son côté “fun”. Cependant, il est évident que tous ces critères bien qu identifié n’ont pas la même importance dans la prise de décision et que la définition de valeur de pondération est une solution afin de les prioriser.A noter que si les critères n’imposent d'être numérique, il est préférable de les manipuler comme tel le plus souvent possible afin de faciliter la compilation des “notes” des différentes alternatives et faciliter les comparaisons (chose plus difficile à mener si les critères sont des espace numérique tel que [faible, bon, fort])
Solutions Alternatives
L’identification des solutions alternatives élaborées lors de Brainstorming va permettre de raffiner le besoin initial en le considérant selon différentes approches et ainsi favoriser l'innovation. Cette phase s’accompagne également d’un état de l’art permettant de positionner les alternatives standards face à celles conçues initialement. La constitution des alternatives va généralement faire apparaître de nouveaux critères.Méthode d'évaluation
La sélections de méthodes d'évaluation des solutions alternatives est entièrement dépendante, d’une part, du domaine considéré par la solution initiale envisagé mais, d’autre part, aussi par les solutions alternatives qui peuvent offrir des approches très différentes. En effet, entre une solution automatique et manuelle, il faudra reconsidérer les critères d'évaluations afin de parvenir à un ensemble comparable car des critères peuvent exister dans des approches et ne pas avoir de sens dans d’autres. Il conviendra alors de déterminer si ce critère est pertinent et doit être pris en compte.De façon générale, les méthodes d’évaluations peuvent être choisi parmi celles déjà employé par les communautés. Basiquement, des tests peuvent être employés en réalisant par exemple un POC (Proof of concept) mais il est aussi possible de réaliser de la modélisation et de la simulation où de manière encore plus pousser, réaliser des études statistiques (selon des approches fréquentiste ou bayésienne, mais nous y reviendrons dans un prochain article)
Evaluation
L'évaluation des solutions alternatives est la phase coeur du DAR. Elle consiste en l’application des méthodes considérées afin de noter les alternatives selon les différents critères et permettre leur comparaison. Ce processus peut être itératif afin d'affiner les résultats et minimiser l’incertitude sur la reproductibilité. Enfin elle permet de prendre du recul sur la pertinence des critères et de faciliter leur ajustement en terme de poid sur la décision qu’il faudra prendre.Sélection
La sélection de la solution recommandée est la dernière phase du DAR dans laquelle, suite à l'évaluation et la compilation des résultats, un choix rationnellement éclairé est effectué au vue des résultats avec la prise en compte objective des avantages, des inconvénients, des coûts et des risques. La conclusion du DAR est alors produite afin de consolider le choix réalisé.Conclusion
La finalisation du DAR passe enfin par la constitution d’un document compilant l’ensemble des informations collectés ainsi que l’argumentation justifiant les critères choisis, les alternatives considérées, etc Dans le but de consolider l’histoire d’un projet et des choix effectué au sein de l’entité, ce document pourra alors faire office de jurisprudence dans le cadre des prochaines décisions à prendre.Références
[1] https://www.iso.org/fr/iso-9001-quality-management.html[2] https://fr.wikipedia.org/wiki/Capability_Maturity_Model_Integration
[3] https://bee4win.com/lavant-vente-cest-quoi/
[4] https://msdn.microsoft.com/fr-fr/library/ee461556.aspx
[5] https://cmmiinstitute.com/cmmi
mardi 24 avril 2018
SOLID
Aujourd'hui avec un court article, nous allons traiter d'un acronyme. L'acronyme en question est SOLID. Il s'agit d'un acronyme traitant des 5 recommandations de base les plus importantes de la programmation orienté objet [1].
Ainsi l'acronyme signifie:
S pour Single responsibility principle, signifiant qu'une entité ne doit avoir qu'une seul préoccupation et donc ne répondre qu'à une problématique. Cela suit le principe d'analyse en décomposition permettant de dissocier chacun des éléments du système. Généralement ce principe s'applique en premier lieu aux classes (en POO) cependant il est largement admis qu'il est généralisable en l'adaptant au niveau d'abstraction considéré. Ainsi, on retrouvera la même logique sur des composants mais aussi dans les approches de programmation fonctionnelle.
O pour Open/closed principle. Ce principe est à considérer dans la continuité du principe précédent. C'est à dire que si une entité ne considère qu'un seul problème, afin de garantir cette propriété, elle ne doit pas permettre sa modification sinon, soit elle ne répond plus au problème initial soit elle répond a plus que celui ci. Par contre afin de permettre la composition et l'agrégation des fonctions, une entité doit permettre et même faciliter son extension. ainsi en POO on utilisera les mécanismes bien connu d'héritage ou d'encapsulation permettant de compléter ou d'associer des comportements aux sein d'entité dont c'est justement l'unique rôle.
L pour Liskov principle. Rarement violé ce principe impose que les sous types d'une entité doivent continuer à respecter le contrat de base de celle ci et ne pas la transformer, seulement l'étendre. Ainsi grâce à ce principe, la substitution d'une entité par l'un de ses sous types est transparent.
I pour Interface segregation principle. Rejoignant une nouvelle fois le premier principe, celui ci nous pousse à favoriser la construction d'interfaces multiples mais individuelle plutôt qu'une interface agrégeant l'ensemble des contrats à réaliser. Ainsi la maintenabilité s'en trouve augmenté et grâce au précédent principe, une entité bien que potentiellement défaillante selon une interface peut rester fonctionnelle selon une autre (sinon toutes l'auraient été)
D pour Dependency inversion principle est la aussi la continuité du précédemment principe en considérant que les dépendances, si elles sont construite sur les entité les plus abstraites, permettent plus de souplesse dans la construction logiciel et facilite la réorganisation et la substitution en vertue du principe de Liskov. Poussé à son extrême, ce principe nous amènera alors naturellement vers les frameworks permettant l'inversion de contrôle et l'injection de dépendances
Si tout cela n'est pas encore très clair, je vous invite à lire cette petite page qui résume parfaitement SOLID dans la vie quotidienne
[2] http://www.arolla.fr/blog/2017/02/principes-solid-vie-de-jours/
Ainsi l'acronyme signifie:
S pour Single responsibility principle, signifiant qu'une entité ne doit avoir qu'une seul préoccupation et donc ne répondre qu'à une problématique. Cela suit le principe d'analyse en décomposition permettant de dissocier chacun des éléments du système. Généralement ce principe s'applique en premier lieu aux classes (en POO) cependant il est largement admis qu'il est généralisable en l'adaptant au niveau d'abstraction considéré. Ainsi, on retrouvera la même logique sur des composants mais aussi dans les approches de programmation fonctionnelle.
O pour Open/closed principle. Ce principe est à considérer dans la continuité du principe précédent. C'est à dire que si une entité ne considère qu'un seul problème, afin de garantir cette propriété, elle ne doit pas permettre sa modification sinon, soit elle ne répond plus au problème initial soit elle répond a plus que celui ci. Par contre afin de permettre la composition et l'agrégation des fonctions, une entité doit permettre et même faciliter son extension. ainsi en POO on utilisera les mécanismes bien connu d'héritage ou d'encapsulation permettant de compléter ou d'associer des comportements aux sein d'entité dont c'est justement l'unique rôle.
L pour Liskov principle. Rarement violé ce principe impose que les sous types d'une entité doivent continuer à respecter le contrat de base de celle ci et ne pas la transformer, seulement l'étendre. Ainsi grâce à ce principe, la substitution d'une entité par l'un de ses sous types est transparent.
I pour Interface segregation principle. Rejoignant une nouvelle fois le premier principe, celui ci nous pousse à favoriser la construction d'interfaces multiples mais individuelle plutôt qu'une interface agrégeant l'ensemble des contrats à réaliser. Ainsi la maintenabilité s'en trouve augmenté et grâce au précédent principe, une entité bien que potentiellement défaillante selon une interface peut rester fonctionnelle selon une autre (sinon toutes l'auraient été)
D pour Dependency inversion principle est la aussi la continuité du précédemment principe en considérant que les dépendances, si elles sont construite sur les entité les plus abstraites, permettent plus de souplesse dans la construction logiciel et facilite la réorganisation et la substitution en vertue du principe de Liskov. Poussé à son extrême, ce principe nous amènera alors naturellement vers les frameworks permettant l'inversion de contrôle et l'injection de dépendances
Si tout cela n'est pas encore très clair, je vous invite à lire cette petite page qui résume parfaitement SOLID dans la vie quotidienne
Références
[1] http://blog.xebia.fr/2011/07/18/les-principes-solid[2] http://www.arolla.fr/blog/2017/02/principes-solid-vie-de-jours/
lundi 16 avril 2018
Les tests logiciels
Problématique
Dans le développement logiciel, la plus grande des préoccupations est que ce qui est attendu par le client soit effectivement ce qui sera livré. Pour répondre à cette problématique, le client mettra probablement en place des moyens permettant de faire la recette du logiciel livré et vérifier que les fonctionnalités attendues sont bien présentes. Attendre cette étape du processus serait un grave erreur. Ainsi, il importe de faire ces vérifications avant cette étape et afin de garantir le moins de mauvaises surprises possibles.Contexte
Pour faire ces vérifications, l’approche classique consiste à définir un plan de stratégie de test (STP). A ce stade j’en imagine déjà certains en train de dire, pfff, des tests, de la doc, tout ca c’est ca a rien à voir avec le développement logiciel! Et bien ils se trompent car définir une stratégie de test est tout aussi important que d’avoir formalisé les besoins (auxquels les tests vont données des moyens de validation), d’avoir défini une architecture (qui sera aussi validé par les tests) où d’avoir un processus de développement (qui pourra s’appuyer sur les tests pour qualifier le logiciel et permettre son déroulement).Ainsi le test est partout, dans tous les processus, à toutes les étapes, à tous les niveaux d’abstractions et il permet même de faciliter le développement en guidant le développeur en adoptant la démarche TDD (test driven development).
Dans cet article je vous propose dans un premier temps de revenir sur la définition d’un test puis de regarder les éléments faisant partie du plan de stratégie et d’identifier l’ensemble des types de tests qui peuvent être réalisés, leur objectifs et l’outillage éventuellement nécessaire pour les mettre en oeuvre.
Définition du test
Un test est une procédure permettant pour une assertion données de déclarer si celle ci est vrai ou fausse. Cette assertion est généralement la confrontation du résultat d’un calcul où d’une procédure comparé avec un résultat attendu.La procédure permettant la mise en oeuvre d’un test consiste généralement à considérer l'élément à tester comme une noire de façon à ne pas préjuger de son implémentation et de ne se fier qu'à ses contrats d’interfaces (Par exemple pour une méthode, ce sont ses paramètres et retour, pour un composant, ce sont ses interfaces, pour un web service, le wsdl).
Enfin il reste à définir des scénarios d'exécution à l’aide de jeux de données d’entrées et de données attendues. A noter que si le composant a tester nécessite des dépendances, alors il convient de les déboucher avec des artefacts simulant le fonctionnement de celles-ci.

L'exécution des tests se doit alors de couvrir l’ensemble des fonctions attendues du composant,reproductible et constante dans le temps. Test de recette
Tout d’abord et nous venons d’en parler, il a le test de recette. Ce test est un test permettant au client de valider la livraison sur un certain périmètre fonctionnel plus où moins grand selon les modifications apportées au logiciel dans la version.
C’est en toute logique l'équipe en charge du développement qui va proposer le protocole et le contenu du test de recette afin d’une part de permettre au client de le valider en amont de la livraison et également faciliter la reproductibilité de celui-ci. Ainsi sur des livraisons mineures et si la confiance est suffisante, ces tests pourront même être joué par l'équipe sur la base du protocole validé. Un compte rendu des tests sera ensuite livrés en même temps que le produit afin d’en attester des fonctionnalités. Le client aura alors toute la latitude de rejouer où non la version et les tests afin d’en vérifier les résultats prétendu obtenu par l'équipe.
Dans le plan de stratégie de test, le test de recette est évidemment indispensable et forcément majeur. Cependant, il n’est pas réaliste de croire que d’une part faire des tests pour la livraison est faisable surtout après plusieurs semaines de développement, et d’autre part que le client va s’en satisfaire.
Test du développement et de l’intégration continue
Pour répondre a ces problèmes, généralement, il est proposé de réaliser des tests en différents point du processus de développement et d’intégration du logiciel et ce de façon régulière (de préférence journalière). Cette approche qui nécessite souvent d'être automatisé (on peut même affirmer que c’est incontournable) permet l’identification au plus tôt des régressions éventuellement. Nous avions vu le principe de l'intégration continu dans l’article [1], il s’agit ici textuellement de la mise en oeuvre de cette partie du processus.Différents types de tests pourront être distingué :
- Les tests unitaires
- Les test technique
- Les test d’interface
- Les test integration
- Les test de Base de données
- Les test d’IHM
- Les test fonctionnel
- Les test bout en bout
- Les test de qualimétrie
L’outil classique et le plus polyvalent pour répondre à la grande partie des mises en oeuvre des tests est indéniablement Robotframework [12]. Dédié le plus souvent aux tests fonctionnels, il permet de construire des DSL modélisant l’environnement des tests à réaliser permettant de l’adapter à tout type de test, que ce soit technique que fonctionnel. Tests unitaires
En entré du processus d’IC, viennent les branches de développement. Ces branches sont issues du travaille des développeurs qui auront, selon les aspects techniques et les éléments fonctionnels impactés, ajoutés ou mis à jours les tests unitaires.
Les test unitaires sont des tests locaux sur les éléments du développement en cours dont le périmètre doit se restreindre au maximum aux briques essentielles de ce développement. Généralement les tests se limitent à la granularité minimal du code, en proposant un cadre exhaustif d'utilisation d’une méthode où plus largement d’une classe. Pour cela, de nombreux frameworks sont disponibles fournissant des primitives de tests facilitant la vérification de résultats attendus (le plus connu étant JUnit [2]) où fournissant des moyens de simplifications pour la mise en oeuvre des tests en facilitant soit la construction de jeux de données ou le bouchonnage de dépendances par la construction de Mock (soutenu par le framework Mockito [3] par exemple).
Les démarches de construction des tests unitaires sont variables. La pratique courante et que le développeur en charge de la réalisation d’une évolution se charge également de la réalisation du test. Ceci est considéré comme une mauvaise pratique pour deux raisons:
Tout d’abord, un test a pour but de démontrer une erreur dans la réalisation d’une fonction or généralement, les gens sont plutôt d’accord avec eux même. Il est vrai que parfois en écrivant le test, on se rend compte d’oubli mais le test n’est pas initialement le moment de comprendre le besoin, il ne sert qu'à démontrer le bon fonctionnement. On préconise donc que le test soit écrit par un autre développeur sachant que cela nécessite alors que les deux développeurs se mettent d’accord avec les interfaces du composant à tester/réaliser.
Second point, on préconise également pour faciliter la mise en oeuvre de la fonction que les tests soient défini préalablement afin de faciliter la compréhension de la fonction, la validation de celle-ci et d’avoir une mesure plus évidente de l’avancement. On appelle cette démarche le TDD (Test Driven Development)
De façon générale, les tests unitaires sont joués par le développeur lors du développement mais aussi lors de corrections dans l’objectif de contrôler la non régression technique où fonctionnel car même si les TU doivent être développé indépendamment, le code l’est rarement et parfois, avec des mocks, modifier une fonction et son test ne suffit pas pour garantir que tous les tests continueront à être valide. Ainsi de façon a ce que l'exécution des tests ne soient pas trop long il est indispensable de les faire simple et concis. Car il est évident que si l'exécution des tests prennent plus de 30 min à être exécuté par le développeur, ils auront à terme plus de chance de ne plus être exécuté….
Test technique
Le test technique est un test de haut niveau dont la portée n’est pas de garantir un besoin client mais la validation de où d’une partie de la solution technique. Ainsi un test technique ne cherche pas à garantir le but mais le moyen. Par exemple, on peut considérer que les TU sont une sorte de test technique, tout comme les tests sur des web services, d'intégration, de charge, de robustesse, de base de données d’IHM où encore de qualimétrie, etc…Généralement si le processus de développement définit convenablement son référentiel documentaire et que celui ci s’appuie sur des exigences, alors le test technique permet la validation des exigences du cahier de conception (où d’architecture)
Test intégration
Les tests d'intégration sont des tests techniques primordiaux dans la vie de systèmes logiciels. On peut les considérer de deux sortes:des tests d'intégration horizontaux qui traitent généralement des problématiques d'intégration propre aux choix d’architectures telles que les architectures modulaires et/ou réparti
des test verticaux traitant de la capacité de compatibilité des logiciels entre eux (par exemple, la capacité d’installation, configuration, désinstallation, mise a jours sur une où plusieurs type d’OS où dans des conteneurs d’applications différents)
Ces test sont souvent complexe à mener car difficile à automatiser et nécessitant une expertise transverse à l’ensemble des composants. De plus, les outils utilisables restent très spécifiques à chaque type d’interface à intégrer ainsi, il sera nécessaire de constituer des équipes conséquentes pour gérer une trop forte hétérogénéité surtout dans le cas de systèmes logiciels conséquent qui nécessitent souvent des plateformes d'intégrations dédiés
Test de Base de données
L’utilisation de base de données est incontournable dans les systèmes logiciels actuel. Il s’agit généralement d’un composant critique du système contenant toutes les informations relatives à l’exploitation du métier du client.La vérification de base de données consiste généralement en la vérification des accès aux données, à la coherence d’insertion respectant les contraintes d'intégrités et que la suppression de données permet de conserver une base de données également intégrée et cohérente.
Pour faire ce genre de test, on pourra employer des outils facilitant la création, suppression et modification des données tels que Liquibase [4], dbdeploy [5] où JHipster [6].
Test d’IHM
Souvent considérés à tort comme des tests fonctionnels, les tests d’IHM sont en fait des tests techniques dont l’objet est la vérification d’ergonomie de l’application (qu’elle soit web où stand alone) et la présence effective des informations et contrôleurs permettant les interactions du client.La confusion entre test fonctionnel et test ihm est simple, elle provient de la simplification de la stratégie de vérification en proposant dans une plateforme d'intégration (donc relativement complète techniquement) des procédures déroulant les cas d’utilisation du client. Ces procédures (généralement réalisées manuellement et considérées comme des tests fonctionnels) sont en fait des tests de recette permettant une couverture non-exhaustive des fonctionnalités. S'ils permettent d’avoir un bon apriori sur le périmètre fonctionnel viable il n’en donne pas une information réelle. De même nous verrons dans un chapitre suivant qu'à l’inverse un test fonctionnel n’est pas forcément un test d’IHM.
La mise en oeuvre de test d’IHM est complexe car la boite noire a tester est l’IHM dans son environnement d'exécution. Ainsi le point d’entrée d’une IHM est généralement un écran, un clavier et une souris et donc s’assimile souvent à des images corrélées à des événements claviers/souris ainsi que la position de cette dernière.
Pour répondre à ce genre de problématiques, il existe deux approches: La première consiste a considérer l'écran tel quel le voit l’utilisateur et d’enregistrer les actions utilisateurs et déplacement souris. Ainsi, suite a l’enregistrement il sera possible de rejouer le test. Cette approche est proposé par des outils comme Selenium [7] et Sikuli [8]. Bien que peu robuste aux modifications même infime d’IHM, ces approches sont difficiles à maintenir. La seconde approche consiste à utiliser des outils d’introspection capable d’identifier les composants de l’IHM pendant leur exécution et de simuler les actions d’un utilisateur. Dans cette approche, l’avantage est clairement la simplification des tests qui alors devient des tests classiques presque unitaire. Cependant, tous les framework d’IHM ne permettent cette approche car si en Java Swing, il sera facile d’utiliser Fest [9], dès que l’on utilisera une IHM Web, il sera nécessaire de se rabattre sur des tests utilisant l’approche précédente.
Test de qualimétrie
Les tests de qualimétrie sont des tests technique portant sur la qualité du logiciel en terme de vulnérabilité, maintenabilité, bug potentiel, couverture de test et duplication de code. Ces informations sont élaborées par des outils exploitant les phases de compilations, de test unitaire où de tests spécifiques. Ainsi dans ce contexte le plus connu est probablement aujourd’hui Sonar [10] qui permet la consolidation de ces différents critères.A noter quand dans la pratique, ces informations sont trop souvent négligé à tort car les configurations par défaut s'appuient sur les recommandations construites par les communautés et fournissent un cadre formatif très poussé pour comprendre beaucoup de subtilités des langages traités
Test de charge
Les tests de charges sont des tests techniques où l’application est mise en situation de fonctionnement nominal avec des fluctuations sur les débits des flux entrant.Le but de ce type de test est de visualiser le comportement du système dans les cas normaux et également aux limites, lorsque celui-ci est sollicité de façon exagérée. On procédera souvent a des mesure de temps de traversé des données et des temps de réponse du composant pour la prise en compte des sollicitations.
Ces tests ne sont pas souvent mise en oeuvre car étant coûteux à mettre en oeuvre même si des outils existent comme JMeter [11]
Test de robustesse
Le test de robustesse, comme le test de charge est un type de test technique où le but est la mise en situation critique du logiciel soit sur des cas d’utilisation non prévu, soit dans les cas de défaillances pendant lesquels, le logiciel doit être en mesure soit de continuer à assurer le service soit au mieux permettre aux services parallèles de continuer à fonctionner. Les tests de robustesses sont à définir sur de nombreux plans, des TU aux tests d’IHM, aux tests de base de données où même de charge.Le cas typique du test de robustesse est la résistance à des données d’entrée corrompu susceptible de corrompre le fonctionnement.
Test fonctionnel
Souvent confondu avec les tests d’IHM comme nous en avons parlé précédemment, les tests fonctionnels sont défini sur la base de la définition du besoin du client. Ils permettent de vérifier la faisabilité et la cohérence fonctionnelle du besoin en formalisant et scénarisant son utilisation. Ainsi le test fonctionnel (et ses UC) sert de référentiel pour la couverture complète du besoin et est généralement la base pour la constitution des tests de recettes qui en forme souvent un sous ensemble lorsque ces derniers traitent des IHM.Test bout en bout
Lest test bout en bout regroupent l’ensemble des tests permettant la traversé complète du système logiciel, du point d’entré jusqu’aux bases de données en incluant les retours de données éventuels. Selon le test, cela ne signifie pas forcément la même chose, il est évident que toutes les fonctions ne réalisent pas les mêmes trajets, mais c’est l'intérêt de ces tests finalement: fournir une couverture exhaustive de l’ensemble des traversés possibles du système.Dans ce genre de test, l’utilisation d’outils comme Robotframework est indispensable en permettant de construire des DSL spécifique a chaque type de test bout en bout rencontré. Cela nécessitera cependant la création de bouchons afin donner l’impression que les systèmes externes sont opérant.
Conclusion
Voilà nous arrivons au bout de ce long article sur les tests. Ils sont souvent complexe à réaliser et s’appliquent sur divers aspects du système logiciel, a tous les niveaux d’abstraction et selon des méthodes et des approches variés. Pourtant même les tests ne sont pas forcément à la hauteur du système logiciel qu’ils doivent validé, Ils sont indispensables à la qualité du produit et à la confiance que le client pourra donner au système logiciel. Ainsi, il n’est jamais bon de négliger les testsRéférences
[1] http://un-est-tout-et-tout-est-un.blogspot.fr/2018/02/integration-continue.html[2] https://junit.org/junit5/
[3] http://site.mockito.org/
[4] https://www.liquibase.org/
[5] http://dbdeploy.com/
[6] https://www.jhipster.tech/
[7] https://www.seleniumhq.org/
[8] http://www.sikuli.org/
[9] https://un-est-tout-et-tout-est-un.blogspot.fr/2018/01/test-dihm-fest-util.html
[10] https://about.sonarcloud.io/
[11] https://jmeter.apache.org/
[12] http://robotframework.org/
mardi 10 avril 2018
IA : Principe de l'automatique
Souvent assimilé à une sous classe (ou parfois une sur classe) de l’informatique, l’automatique est en fait une branche de la cybernétique au même titre que l’informatique [1]
 L’automatique est l’ensemble des méthodes et théories mathématiques relevant de l'étude et la modélisation des systèmes (dynamiques) et de leur commande. Derrière cette définition un peu vaste se pose la question de la compréhension des conditions amenant un système dans un état particulier (voir l’ensemble des états atteignables) et comment, par la modélisation de son comportement, éventuellement optimiser ce comportement ou le limiter.
L’automatique est l’ensemble des méthodes et théories mathématiques relevant de l'étude et la modélisation des systèmes (dynamiques) et de leur commande. Derrière cette définition un peu vaste se pose la question de la compréhension des conditions amenant un système dans un état particulier (voir l’ensemble des états atteignables) et comment, par la modélisation de son comportement, éventuellement optimiser ce comportement ou le limiter.
L'automaticien a pour rôle de définir cette modélisation et de construire en conséquence une loi de commande pour ce système en suivant l’un de ces deux objectifs : soit simplement d’aider le système à atteindre son objectif et à converger plus rapidement, à garantir sa convergence, ou à minimiser son erreur, soit réduire les comportements non attendu, afin d'éviter sa rupture ou plus grave qu’il ne mette en danger des individus.
La plupart des systèmes de contrôle commande actuels reposent sur des systèmes informatiques, mais ce n’est pas une condition d'existence car ces systèmes ont eut leur équivalent mécanique ou électronique. Il est vrai que si l’on considère l’informatique comme le traitement pure et simple de l’information il serait acceptable de considérer l’informatique comme une branche de l’automatique ou le système dynamique étudié est l’information et les lois de commande à produire comme l’ensemble des transformations opérables en vue d’obtenir d’autres informations optimisés et/ou filtrés.
Seulement, tout ceci est très réducteur car l’informatique s’est largement émancipé de ce genre de préoccupation et aujourd’hui les deux disciplines se distinguent clairement même si elles interagissent encore beaucoup et c’est d’ailleurs sur ce point que je souhaite concentrer cet article : voir les principes de l’automatique en nous concentrant non sur ce que l’informatique peut apporter à l’automatique (je laisse aux automaticiens de faire ce travail) mais sur ce que l’automatique apporte à l’informatique.
En effet, informatique et automatique sont des disciplines qui tirent partie l’une de l’autre. Et jusqu'à ces dernières années on pouvait dire que c'était l’automatique qui tirait le plus partie de l’informatique. Aujourd’hui cependant, on ne peut s'arrêter à cette vision car cette dépendance s’inverse : l’informatique vient de plus en plus chercher les concepts de l’automatique pour adresser ses propres problèmes, c’est pourquoi il est important de regarder ce qui forme les concepts de base de l’automatique afin de mieux en comprendre l’héritage dans les approches actuelles comme le big data, le machine learning, les réseaux de neurones ou plus globalement l’IA qui seront l’objet des articles futur.
Ainsi comme nous l’avons évoqué, l’automatique repose sur deux axes, l'étude des systèmes d’un côté et l'élaboration d’une loi de commande de l’autres, ce dernier axe étant généralement nommé contrôle-commande.
 De cette étude viendra alors ensuite par l’utilisation d’outils mathématiques ou de langage de modélisation des objets appelés modèles. Nous ne rentrerons pas dans la question de qu’est ce que la modélisation (sujet déjà traité ici []) mais l’idée ici est d’avoir une entité, représentant le système nous permettant de déduire des propriétés structurelles ou comportementales que ce dernier possède (il est bien sûr très important de toujours garder en tête que le modèle n’est pas le système mais qu’une abstraction de celui ci avec ses propres limites) Donc, ces modèles nous permettent de discriminer le système selon différents critères comme sa nature, sa dynamique, etc.
De cette étude viendra alors ensuite par l’utilisation d’outils mathématiques ou de langage de modélisation des objets appelés modèles. Nous ne rentrerons pas dans la question de qu’est ce que la modélisation (sujet déjà traité ici []) mais l’idée ici est d’avoir une entité, représentant le système nous permettant de déduire des propriétés structurelles ou comportementales que ce dernier possède (il est bien sûr très important de toujours garder en tête que le modèle n’est pas le système mais qu’une abstraction de celui ci avec ses propres limites) Donc, ces modèles nous permettent de discriminer le système selon différents critères comme sa nature, sa dynamique, etc.
 Comme il n’est pas forcément possible d’avoir systématiquement la connaissance du bon langage pour chaque cas, il faut être capable de raisonner sur des schéma de principe propre à l’automatique permettant de manipuler les concepts du domaine et élaborer des stratégies de traitement qui pourront s’appliquer à des ensembles de problèmes de même famille. Pour cela, nous avons vu dans le schéma xxx qu’un système existe dans un environnement, qu’il répond à une fonction traitant de paramètre d’entrée afin de produire des données de sorties
Comme il n’est pas forcément possible d’avoir systématiquement la connaissance du bon langage pour chaque cas, il faut être capable de raisonner sur des schéma de principe propre à l’automatique permettant de manipuler les concepts du domaine et élaborer des stratégies de traitement qui pourront s’appliquer à des ensembles de problèmes de même famille. Pour cela, nous avons vu dans le schéma xxx qu’un système existe dans un environnement, qu’il répond à une fonction traitant de paramètre d’entrée afin de produire des données de sorties

Ainsi la figure xxx présente un schéma de principe résumant le fonctionnement d’un système. Si ensuite on projet de lui appliquer une loi de commande, on va alors réaliser l’un des principes les plus important de l’automatique : le feedback ou rétroaction où rebouclage où encore rétropropagation.

Pourquoi autant de termes pour représenter la même chose? Simplement parce que chaque terme s’associe souvent à des domaines autres que l’automatique comme le terme de rétropropagation qui classiquement utilisé dans le domaine de l’IA, du machine learning et du deep learning lorsqu’il est nécessaire de reporter la sortie produite sur les entrées afin d’ “apprendre”.
Bien sur chaque rétroaction s'implémente différemment et cela est conditionné par la nature même du système. Pourtant de façon générale on peut considérer le traitement et les interactions entre le système et la loie de commande comme la mise en relation des éléments du schéma suivant.
 Pourtant ; il n’y a jamais de vérité définitive et selon le type du systèmes, les outils de modélisations choisis, les propriétés que l’on souhaite contrôlé et les moyens d'élaborer la loi de commande, il est possible de trouver des versions simplifiées de cette vue en convergeant vers le schéma déjà présenté (schéma asservissement) qui nous ramène à ce concept fondamental, qu’est le feedback.
Pourtant ; il n’y a jamais de vérité définitive et selon le type du systèmes, les outils de modélisations choisis, les propriétés que l’on souhaite contrôlé et les moyens d'élaborer la loi de commande, il est possible de trouver des versions simplifiées de cette vue en convergeant vers le schéma déjà présenté (schéma asservissement) qui nous ramène à ce concept fondamental, qu’est le feedback.
L'automaticien a pour rôle de définir cette modélisation et de construire en conséquence une loi de commande pour ce système en suivant l’un de ces deux objectifs : soit simplement d’aider le système à atteindre son objectif et à converger plus rapidement, à garantir sa convergence, ou à minimiser son erreur, soit réduire les comportements non attendu, afin d'éviter sa rupture ou plus grave qu’il ne mette en danger des individus.
La plupart des systèmes de contrôle commande actuels reposent sur des systèmes informatiques, mais ce n’est pas une condition d'existence car ces systèmes ont eut leur équivalent mécanique ou électronique. Il est vrai que si l’on considère l’informatique comme le traitement pure et simple de l’information il serait acceptable de considérer l’informatique comme une branche de l’automatique ou le système dynamique étudié est l’information et les lois de commande à produire comme l’ensemble des transformations opérables en vue d’obtenir d’autres informations optimisés et/ou filtrés.
Seulement, tout ceci est très réducteur car l’informatique s’est largement émancipé de ce genre de préoccupation et aujourd’hui les deux disciplines se distinguent clairement même si elles interagissent encore beaucoup et c’est d’ailleurs sur ce point que je souhaite concentrer cet article : voir les principes de l’automatique en nous concentrant non sur ce que l’informatique peut apporter à l’automatique (je laisse aux automaticiens de faire ce travail) mais sur ce que l’automatique apporte à l’informatique.
En effet, informatique et automatique sont des disciplines qui tirent partie l’une de l’autre. Et jusqu'à ces dernières années on pouvait dire que c'était l’automatique qui tirait le plus partie de l’informatique. Aujourd’hui cependant, on ne peut s'arrêter à cette vision car cette dépendance s’inverse : l’informatique vient de plus en plus chercher les concepts de l’automatique pour adresser ses propres problèmes, c’est pourquoi il est important de regarder ce qui forme les concepts de base de l’automatique afin de mieux en comprendre l’héritage dans les approches actuelles comme le big data, le machine learning, les réseaux de neurones ou plus globalement l’IA qui seront l’objet des articles futur.
Ainsi comme nous l’avons évoqué, l’automatique repose sur deux axes, l'étude des systèmes d’un côté et l'élaboration d’une loi de commande de l’autres, ce dernier axe étant généralement nommé contrôle-commande.
Etude des systèmes
L’etude des systemes est un vaste domaine et couvre bien plus de champs que celui de l’automatique. Cela peut traiter du comportement de véhicules terrestres, du comportement des fluides dans des conditions particulières, du comportement des foules, ou même de la météo. En fait à partir du moment on l’on considère une entité physique dans un environnement bien déterminé, nous faisons de cette considération une étude.Loi de commande
Le rôle de la commande est alors de se focaliser sur l’un des axes de ses propriétés (mise en évidence par les modèles adéquat) afin de, par exemple, limiter un comportement, ou à l’inverse en lui permettant d’en avoir de nouveau, etc… Le choix des modèles choisi est très important car il va de soit que les outils permettant de les construire ne sont pas les même selon le besoin de l'étude et également les besoins de contrôle commandes. Pour comprendre le comportement d’un véhicule, il sera nécessaire de s’appuyer sur des équations différentielles pour représenter la dynamique du système alors que dans l'étude d’une population, des outils statistiques seront probablement plus adapté mais de la même façon, afin de permettre la commande d’un système, il faudra également produire des modèles en adéquation avec l’objectif de la commande souvent lui même représenté par un modèle.Ainsi la figure xxx présente un schéma de principe résumant le fonctionnement d’un système. Si ensuite on projet de lui appliquer une loi de commande, on va alors réaliser l’un des principes les plus important de l’automatique : le feedback ou rétroaction où rebouclage où encore rétropropagation.
Pourquoi autant de termes pour représenter la même chose? Simplement parce que chaque terme s’associe souvent à des domaines autres que l’automatique comme le terme de rétropropagation qui classiquement utilisé dans le domaine de l’IA, du machine learning et du deep learning lorsqu’il est nécessaire de reporter la sortie produite sur les entrées afin d’ “apprendre”.
Bien sur chaque rétroaction s'implémente différemment et cela est conditionné par la nature même du système. Pourtant de façon générale on peut considérer le traitement et les interactions entre le système et la loie de commande comme la mise en relation des éléments du schéma suivant.
Conclusion
Voila, je n’irais pas plus loin dans cet article déjà assez long surtout que le but était surtout d’introduire la notion de feedback, qui va nous être d’une aide indispensable dans le traitement de l’IA dont les articles vont venir très prochainement.Références:
[1] https://interstrate.com/2016/10/18/cybernetique-et-theorie-des-systemes/samedi 7 avril 2018
Design pattern : MVC
Le pattern MVC est l’un des patterns les plus connu du monde de l'ingénierie logicielle. Celui ci est peut être même le représentant et le plus emblématique de la notion de pattern de conception. Cependant ce pattern a beau être le plus connu, il est aussi probablement l'un des plus complexe et des plus diversifié dans ses implémentations.
Ce pattern MVC est avant tout un pattern de conception. Il a ensuite été généralisé en tant que pattern d'architecture mais aussi adapté (pour ne pas dire déformé) pour des contextes de conception et de réalisation un peu plus éloigné de son objectif initial.
Dans son principe, et nous l'avons déjà souvent vu avec les autres pattern, le pattern MVC mène lui aussi à la separation des preoccupations en s'attachant à traiter la problématique de l'indépendance des interfaces homme machine (et de ses interactions) et des composantes métiers du logiciel. Bien sur, si cela a été son but initial, aujourd'hui son utilisation a plus de cadre d'application que cela, et de nombreuse déclinaisons sont possibles tant que le soucis de découplage est présent au sein d'entités communicantes de façon cyclique (nous allons voir rapidement pourquoi).
Ainsi pour procéder a ce découplage, MVC propose de découpler la solution logicielle en 3 entité distinctes que sont le Modèle, la Vue et le Controller (d'où MVC... héhé!).

Je vais éviter de faire des paraphrases sur le rôle de ces différents éléments mais malgré tout je n'utiliserai pas non plus d'exemple pour illustrer ces concepts car cela dénaturerait l'objet initial de ce pattern qui a la base ne définit pas spécifiquement de moyen d'implémentation. Dans l'explication qui sera donnée, on pourrait aussi avoir l'impression que nous définissons les choses sur la base des autres définition donnant l'impression d'une explication un peu cyclique mais dans le principe, le MVC est cyclique donc... finalement c'est normal.
Le concept de modèle dans le MVC peut être vu (dans un premier temps car en fait non mais ca peut etre plus simple de prime abord expliqué ainsi) comme l'élément pivot du pattern. Le modèle concentre l'ensemble des informations qui seront nécessaires à la vue. Première confusion possible, le modèle n'est pas le modele metier de votre application, il n'est que le modèle de la vue et des informations qui devront y être exposé. C'est subtile mais important nous verrons pourquoi après.
La vue justement est le porteur de l'information graphique, elle définit structurellement la manière dont seront agencées les données extraites du modèle et les encapsulant dans des éléments décoratifs spécifiques à la technologie d'interface en se limitant justement au côté affichage.
Le contrôleur prend ensuite le relais justement sur les éléments de la vue susceptible d'être le lieu d'émission d'événements consécutif aux actions de l'utilisateur. Attention, le contrôleur n'est pas derrière la vue ou même dans la vue mais il est la facette événementielle de celle ci permettant la gestion des actions. Bien sûr, nous avons le sentiment que l'action est corrélé avec chacun des éléments de la vue mais cela est dû à une propriété particulière du pattern MVC que nous détaillerons par la suite, la composition. Gardons en tête pour l'instant que le contrôleur a pour rôle d'intercepter les actions utilisateur et en conséquence de quoi d'aller indiquer au modèle qu'une modification est à prendre en compte.

Nous voyons donc que la structure cyclique du pattern MVC est importante. Le modèle renseigne la Vue qui expose les actions possible que le contrôleur va intercepter et solliciter le modèle pour sa mise à jour qui du coup va permettre à la vue de se mettre à jour.
Structurellement on a compris comment cela fonctionne. Cependant nous n'avons pas parler de comment le pattern va s'implementer. Pour implementer le pattern MVC, il est important de comprendre que sa préoccupation principale est le découplage, que ce soit bien sur des aspects représentations, contrôle ou gestion des données mais aussi et surtout au niveau de la granularité. Ainsi ce pattern n'est pas forcément contraint de fonctionner en trinôme. Pour un même modèle, plusieurs vue peuvent exister, celle représentant l'information a sa manière et avoir en conséquence des contrôleurs spécifiques pour chacunes d'elle ou pas si l'action résultant est finalement la même (on pourrait imaginer des boutons tous différents mais ayant la même finalité....) De même un pattern MVC peut aussi être une composition de pattern MVC permettant par exemple une gestion coordonnées de fenêtre et de taille. On remarque justement très bien ici que pour plusieurs modèles et vues (éventuellement encapsulé les unes dans les autres) on n'aurait qu'un seul contrôleur. Ainsi les possibilité sont réellement très grande tant le découplage de ces aspects facilite les combinaisons de comportements.

Maintenant que nous avons vu de quoi le pattern retourne, nous pouvons traiter de son implémentation et des limites que ces dernières imposeront. Initialement le pattern MVC est apparu avant l'explosion du Web dans le langage smalltalk (une merveille d’ailleur… dommage…)Il a ensuite été consolidé sur les interfaces graphiques des clients Lourd comme AWT ou swing. Ainsi, le pattern MVC s’est défini principalement sur le pattern observateur ou chaque élément de pattern MVC est observateur d’un élément mais aussi observé par un autre élément. Ainsi, la vue est observateur du modèle qui est observateur du ou des contrôleurs (ces derniers étant indirectement les observateurs de la vue en interceptant les événements). C’est ainsi grâce à l’observateur que le pattern MVC tire non seulement ce découplage mais aussi sa réactivité.
Ce modèle du MVC a longtemps été le standard de ce pattern et on le retrouve implémenté sous cette forme dans la plupart des frameworks graphiques standard. Cependant avec l'expansion du web, et la mise en communication de plus en plus forte des interfaces clientes (appelé front) avec les couches server (appelé back), il a fallu trouver un moyen efficace de rationaliser la conception des IHM et leur communication avec le métier. Ainsi de façon naturelle et évidente, et comme elle avait fait ses preuves, on s’est naturellement tourné vers le pattern MVC.
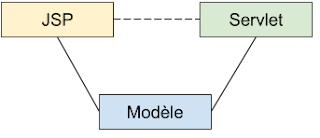 Ainsi, le pattern MVC est aujourd’hui encore largement répandu, souvent vendu comme une nouvelle approche alors que vieille comme le monde, l'élément neuf étant surtout la façon de le mettre en oeuvre. On peut évoquer par exemple les approches des Framework JEE (avec le duo Servlet/JSP), le framework Spring MVC ou Django.
Ainsi, le pattern MVC est aujourd’hui encore largement répandu, souvent vendu comme une nouvelle approche alors que vieille comme le monde, l'élément neuf étant surtout la façon de le mettre en oeuvre. On peut évoquer par exemple les approches des Framework JEE (avec le duo Servlet/JSP), le framework Spring MVC ou Django.
 Nous reviendrons sur ces implémentations dans des articles dédié mais ces frameworks usent d’une implémentation spécifique de MVC et de la même manière, d’autres variantes existes comme le modèle MVP (Modèle Vue Présentateur, qui va impliquer la mise en place du présentateur entre la vue et le modèle afin de préparer les données) ou encore le modèle MVVM, porté par microsoft pour son framework silverlight, qui cherche lui aussi à découpler la vue du modèle des données de représentation.
Nous reviendrons sur ces implémentations dans des articles dédié mais ces frameworks usent d’une implémentation spécifique de MVC et de la même manière, d’autres variantes existes comme le modèle MVP (Modèle Vue Présentateur, qui va impliquer la mise en place du présentateur entre la vue et le modèle afin de préparer les données) ou encore le modèle MVVM, porté par microsoft pour son framework silverlight, qui cherche lui aussi à découpler la vue du modèle des données de représentation.
Bien sur ce pattern reste riche et est toujours le sujet de nombreuse recherche. Il est important de bien le connaître afin de savoir non seulement le reconnaître dans ses différentes déclinaison mais il faut aussi savoir l’utiliser dans des contextes où on ne l'attendait pas forcément car s’il est catalogué dans les pattern dédié au IHM, ses principes de bases sont le découplage (pour preuve de l’utilisation massive de l’observateur sur lequel il repose essentiellement) et son utilité dans d’autre couche logiciel ne fait aucun doute (surtout pour concevoir des logiciels réactifs…..)
[2] http://www.msdotnet.co.in/2015/05/difference-between-mvcmvp-and-mvvc.html#.Wsf2RZ9fihc
[3] http://www.interaction-design.org/references/conferences/interact_87_-_2nd_ifip_international_conference_on_human-computer_interaction.html#objectType_journalArticleInConfProceedings__objectID_7547
Ce pattern MVC est avant tout un pattern de conception. Il a ensuite été généralisé en tant que pattern d'architecture mais aussi adapté (pour ne pas dire déformé) pour des contextes de conception et de réalisation un peu plus éloigné de son objectif initial.
Dans son principe, et nous l'avons déjà souvent vu avec les autres pattern, le pattern MVC mène lui aussi à la separation des preoccupations en s'attachant à traiter la problématique de l'indépendance des interfaces homme machine (et de ses interactions) et des composantes métiers du logiciel. Bien sur, si cela a été son but initial, aujourd'hui son utilisation a plus de cadre d'application que cela, et de nombreuse déclinaisons sont possibles tant que le soucis de découplage est présent au sein d'entités communicantes de façon cyclique (nous allons voir rapidement pourquoi).
Ainsi pour procéder a ce découplage, MVC propose de découpler la solution logicielle en 3 entité distinctes que sont le Modèle, la Vue et le Controller (d'où MVC... héhé!).
Je vais éviter de faire des paraphrases sur le rôle de ces différents éléments mais malgré tout je n'utiliserai pas non plus d'exemple pour illustrer ces concepts car cela dénaturerait l'objet initial de ce pattern qui a la base ne définit pas spécifiquement de moyen d'implémentation. Dans l'explication qui sera donnée, on pourrait aussi avoir l'impression que nous définissons les choses sur la base des autres définition donnant l'impression d'une explication un peu cyclique mais dans le principe, le MVC est cyclique donc... finalement c'est normal.
Le concept de modèle dans le MVC peut être vu (dans un premier temps car en fait non mais ca peut etre plus simple de prime abord expliqué ainsi) comme l'élément pivot du pattern. Le modèle concentre l'ensemble des informations qui seront nécessaires à la vue. Première confusion possible, le modèle n'est pas le modele metier de votre application, il n'est que le modèle de la vue et des informations qui devront y être exposé. C'est subtile mais important nous verrons pourquoi après.
La vue justement est le porteur de l'information graphique, elle définit structurellement la manière dont seront agencées les données extraites du modèle et les encapsulant dans des éléments décoratifs spécifiques à la technologie d'interface en se limitant justement au côté affichage.
Le contrôleur prend ensuite le relais justement sur les éléments de la vue susceptible d'être le lieu d'émission d'événements consécutif aux actions de l'utilisateur. Attention, le contrôleur n'est pas derrière la vue ou même dans la vue mais il est la facette événementielle de celle ci permettant la gestion des actions. Bien sûr, nous avons le sentiment que l'action est corrélé avec chacun des éléments de la vue mais cela est dû à une propriété particulière du pattern MVC que nous détaillerons par la suite, la composition. Gardons en tête pour l'instant que le contrôleur a pour rôle d'intercepter les actions utilisateur et en conséquence de quoi d'aller indiquer au modèle qu'une modification est à prendre en compte.
Nous voyons donc que la structure cyclique du pattern MVC est importante. Le modèle renseigne la Vue qui expose les actions possible que le contrôleur va intercepter et solliciter le modèle pour sa mise à jour qui du coup va permettre à la vue de se mettre à jour.
Structurellement on a compris comment cela fonctionne. Cependant nous n'avons pas parler de comment le pattern va s'implementer. Pour implementer le pattern MVC, il est important de comprendre que sa préoccupation principale est le découplage, que ce soit bien sur des aspects représentations, contrôle ou gestion des données mais aussi et surtout au niveau de la granularité. Ainsi ce pattern n'est pas forcément contraint de fonctionner en trinôme. Pour un même modèle, plusieurs vue peuvent exister, celle représentant l'information a sa manière et avoir en conséquence des contrôleurs spécifiques pour chacunes d'elle ou pas si l'action résultant est finalement la même (on pourrait imaginer des boutons tous différents mais ayant la même finalité....) De même un pattern MVC peut aussi être une composition de pattern MVC permettant par exemple une gestion coordonnées de fenêtre et de taille. On remarque justement très bien ici que pour plusieurs modèles et vues (éventuellement encapsulé les unes dans les autres) on n'aurait qu'un seul contrôleur. Ainsi les possibilité sont réellement très grande tant le découplage de ces aspects facilite les combinaisons de comportements.

Maintenant que nous avons vu de quoi le pattern retourne, nous pouvons traiter de son implémentation et des limites que ces dernières imposeront. Initialement le pattern MVC est apparu avant l'explosion du Web dans le langage smalltalk (une merveille d’ailleur… dommage…)Il a ensuite été consolidé sur les interfaces graphiques des clients Lourd comme AWT ou swing. Ainsi, le pattern MVC s’est défini principalement sur le pattern observateur ou chaque élément de pattern MVC est observateur d’un élément mais aussi observé par un autre élément. Ainsi, la vue est observateur du modèle qui est observateur du ou des contrôleurs (ces derniers étant indirectement les observateurs de la vue en interceptant les événements). C’est ainsi grâce à l’observateur que le pattern MVC tire non seulement ce découplage mais aussi sa réactivité.
Ce modèle du MVC a longtemps été le standard de ce pattern et on le retrouve implémenté sous cette forme dans la plupart des frameworks graphiques standard. Cependant avec l'expansion du web, et la mise en communication de plus en plus forte des interfaces clientes (appelé front) avec les couches server (appelé back), il a fallu trouver un moyen efficace de rationaliser la conception des IHM et leur communication avec le métier. Ainsi de façon naturelle et évidente, et comme elle avait fait ses preuves, on s’est naturellement tourné vers le pattern MVC.
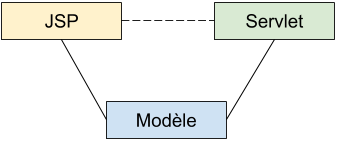
Bien sur ce pattern reste riche et est toujours le sujet de nombreuse recherche. Il est important de bien le connaître afin de savoir non seulement le reconnaître dans ses différentes déclinaison mais il faut aussi savoir l’utiliser dans des contextes où on ne l'attendait pas forcément car s’il est catalogué dans les pattern dédié au IHM, ses principes de bases sont le découplage (pour preuve de l’utilisation massive de l’observateur sur lequel il repose essentiellement) et son utilité dans d’autre couche logiciel ne fait aucun doute (surtout pour concevoir des logiciels réactifs…..)
Références:
[1] https://www.tutorialspoint.com/design_pattern/mvc_pattern.htm[2] http://www.msdotnet.co.in/2015/05/difference-between-mvcmvp-and-mvvc.html#.Wsf2RZ9fihc
[3] http://www.interaction-design.org/references/conferences/interact_87_-_2nd_ifip_international_conference_on_human-computer_interaction.html#objectType_journalArticleInConfProceedings__objectID_7547
lundi 2 avril 2018
InvocationHandler
Nous avions parlé des annotations dans un articles precedents mais nous nous etions arreter au traitements des annotations utilisé dans le code ou dans les class mais pas celles utiliser en runtime.
Je vous propose dans cet article de réemployer l’exemple traité en gardant l’annotation Relation mais de la compléter par exemple d’une annotation Tuple qui permet d'insérer des données dans la table construite par l’annotation Relation. (Au passage on adaptera un peu cette dernière de façon à ce que la Relation ait les attribut qui vont bien…)
Commençons par l’ajout de l’attribut dans notre précédente annotation, au passage on la passe en mode RUNTIME:
Ensuite on va adapter le processeur. On va externaliser la partie en interface avec la BD dans une classe utilitaire permettant de faire la construction de la table avec l’attribut qui va bien:
Voila, normalement on aura un attribut name dans notre table lors du build.
Maintenant on veut qu'à l'exécution, pour chaque objet de type Helloworld on insere dans la table le nom passé en parametre du setter. .
Pour cela on va creer l’annotation AddValue (ok c’est pas original) de façon a pouvoir la placer sur cette methode:
Ainsi on l’utilisera ainsi:
Mais me direz vous, cela ne permet pas vraiment de mapper un quelconque processus d’insertion en base de la donnée! Effectivement car il manque la partie processeur de cette annotation.
Le problème ici c’est que l’annotation doit être traité pendant l'exécution. Alors comment faire?
Et bien tout simplement en utilisant deux patterns, la factory et le pattern proxy. Le premier va nous permettre de masquer l’utilisation du second qui sera couplé à l’invocation handler! Le voila celui la!
Alors avant cela voici ce que nous espérons pouvoir faire:
Et ceci doit nous permettre de l'insertion de Thomas dans la base lors de l’affectation. Pour cela, la factory va utiliser une interface et le prototype de la classe pour construire une instance qui sera en réalité un proxy.
Ainsi on utilise l’api Java Proxy permettant de construire ce proxy a partir de d’une interface identifiant au proxy quels sont les méthodes a wrapper et pour lesquelles, le proxy devra appeler l’InvocationHandler à la rescousse. Voyons comment, ce n’est pas tres compliqué:
Alors tout d’abord, le proxy doit continuer à faire croire que l’on manipule l’objet en question. (la factory etant la pour le tour de passe passe…) Du coup, a peine appelé, l’invocation handler va se charger de se construire un objet du type masqué par le proxy afin de l’utiliser lors de l'appelle effectif des méthodes sur le proxy.

Ceci va permettre de tromper l’utilisateur mais en plus cela va nous permettre de compléter ce comportement. Ainsi le contenu de la méthode invoke décrit la validation de la présence de l’annotation AddValue qui lorsqu’elle est présente va appeler une méthode push Data de notre utilitaire de BD que voici:
Voilà alors bien sur a chaque appele de la méthode setName, l’Invocation Handler va tenter de pousser la nouvelle donnée en BD sans chercher à savoir si c’est cohérent logique ou autre. Pour aller plus loin, il faudrait donner des moyens de vérification si la donnée n’est pas déjà en base ou ajouter un attribut servant de clef primaire…. mais la ca complique beaucoup les chose, et bon on va pas reimplementer JPA… même si l’idée est la même!
Du coup on va s'arrêter là mais j’imagine que vous avez compris l'intérêt de ce pattern surtout lorsqu’il est couplé aux annotations!
[2] https://un-est-tout-et-tout-est-un.blogspot.fr/2017/11/design-pattern-proxy.html
[3] http://un-est-tout-et-tout-est-un.blogspot.com/2017/11/design-pattern-factory.html
Je vous propose dans cet article de réemployer l’exemple traité en gardant l’annotation Relation mais de la compléter par exemple d’une annotation Tuple qui permet d'insérer des données dans la table construite par l’annotation Relation. (Au passage on adaptera un peu cette dernière de façon à ce que la Relation ait les attribut qui vont bien…)
Commençons par l’ajout de l’attribut dans notre précédente annotation, au passage on la passe en mode RUNTIME:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) public @interface Relation { String value(); }
Ensuite on va adapter le processeur. On va externaliser la partie en interface avec la BD dans une classe utilitaire permettant de faire la construction de la table avec l’attribut qui va bien:
public void createRelation(Element e) { Relation relation = e.getAnnotation(Relation.class); String rqt = this.CREATE + e.getSimpleName().toString() + "( " + relation.value() + ATTRIBUT + ");"; System.out.println("Requete :" + rqt); try { PreparedStatement statement = DriverManager.getConnection(DB_URL, USER, PASS).prepareStatement(rqt); System.out.println("Mon element : " + e.getSimpleName().toString()); statement.executeQuery(); } catch (SQLException e1) { e1.printStackTrace(); } }
Voila, normalement on aura un attribut name dans notre table lors du build.
Maintenant on veut qu'à l'exécution, pour chaque objet de type Helloworld on insere dans la table le nom passé en parametre du setter. .
Pour cela on va creer l’annotation AddValue (ok c’est pas original) de façon a pouvoir la placer sur cette methode:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface AddValue { }
Ainsi on l’utilisera ainsi:
@Relation(value = "name") public class HelloWorld { private String name; @AddValue public void setName(String name) { this.name=name; } }
Mais me direz vous, cela ne permet pas vraiment de mapper un quelconque processus d’insertion en base de la donnée! Effectivement car il manque la partie processeur de cette annotation.
Le problème ici c’est que l’annotation doit être traité pendant l'exécution. Alors comment faire?
Et bien tout simplement en utilisant deux patterns, la factory et le pattern proxy. Le premier va nous permettre de masquer l’utilisation du second qui sera couplé à l’invocation handler! Le voila celui la!
Alors avant cela voici ce que nous espérons pouvoir faire:
IHelloWorld o=MyAnnotFactory.mapObject(IHelloWorld.class,HelloWorld.class); o.setName("Thomas");
Et ceci doit nous permettre de l'insertion de Thomas dans la base lors de l’affectation. Pour cela, la factory va utiliser une interface et le prototype de la classe pour construire une instance qui sera en réalité un proxy.
public static T mapObject(Class i,Class t) throws InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException, NoSuchMethodException, SecurityException { T proxy=(T) Proxy.newProxyInstance(MyAnnotFactory.class.getClassLoader(),new Class[]{i}, new MyInvocationHandler(t)); return proxy; }
Ainsi on utilise l’api Java Proxy permettant de construire ce proxy a partir de d’une interface identifiant au proxy quels sont les méthodes a wrapper et pour lesquelles, le proxy devra appeler l’InvocationHandler à la rescousse. Voyons comment, ce n’est pas tres compliqué:
public class MyInvocationHandler implements InvocationHandler { private Object object; public MyInvocationHandler(Class t) { try { this.object = t.newInstance(); } catch (InstantiationException | IllegalAccessException e) { // TODO Auto-generated catch block e.printStackTrace(); } } @Override public Object invoke(Object arg0, Method method, Object[] arg2) throws Throwable { System.out.println("Methode :" + method.getName()); Method m=object.getClass().getMethod(method.getName(),method.getParameterTypes()); for (Annotation annot : m.getAnnotations()) { System.out.println(annot); if (annot.annotationType().equals(AddValue.class)) { System.out.println("je pousse en base"); AnnotDBUtils.getInstance().pushData(object,arg2); return object; } } return method.invoke(object, arg2); } }
Alors tout d’abord, le proxy doit continuer à faire croire que l’on manipule l’objet en question. (la factory etant la pour le tour de passe passe…) Du coup, a peine appelé, l’invocation handler va se charger de se construire un objet du type masqué par le proxy afin de l’utiliser lors de l'appelle effectif des méthodes sur le proxy.
Ceci va permettre de tromper l’utilisateur mais en plus cela va nous permettre de compléter ce comportement. Ainsi le contenu de la méthode invoke décrit la validation de la présence de l’annotation AddValue qui lorsqu’elle est présente va appeler une méthode push Data de notre utilitaire de BD que voici:
public void pushData(Object object, Object[] arg2) { Relation relation = object.getClass().getAnnotation(Relation.class); String rqt = this.INSERT + "\"" + object.getClass().getSimpleName().toLowerCase() + "\" (" + relation.value() + ")" + VALUES + "('" + arg2[0] + "');"; System.out.println("Requete :" + rqt); try { PreparedStatement statement = DriverManager.getConnection(DB_URL, USER, PASS).prepareStatement(rqt); statement.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } }
Voilà alors bien sur a chaque appele de la méthode setName, l’Invocation Handler va tenter de pousser la nouvelle donnée en BD sans chercher à savoir si c’est cohérent logique ou autre. Pour aller plus loin, il faudrait donner des moyens de vérification si la donnée n’est pas déjà en base ou ajouter un attribut servant de clef primaire…. mais la ca complique beaucoup les chose, et bon on va pas reimplementer JPA… même si l’idée est la même!
Du coup on va s'arrêter là mais j’imagine que vous avez compris l'intérêt de ce pattern surtout lorsqu’il est couplé aux annotations!
Références:
[1] http://alain-defrance.developpez.com/articles/Java/J2SE/implementation-dynamique-java-proxy-invocationhandler/[2] https://un-est-tout-et-tout-est-un.blogspot.fr/2017/11/design-pattern-proxy.html
[3] http://un-est-tout-et-tout-est-un.blogspot.com/2017/11/design-pattern-factory.html
Inscription à :
Articles (Atom)