Problématique
Dans le développement logiciel, la plus grande des préoccupations est que ce qui est attendu par le client soit effectivement ce qui sera livré. Pour répondre à cette problématique, le client mettra probablement en place des moyens permettant de faire la recette du logiciel livré et vérifier que les fonctionnalités attendues sont bien présentes. Attendre cette étape du processus serait un grave erreur. Ainsi, il importe de faire ces vérifications avant cette étape et afin de garantir le moins de mauvaises surprises possibles.
Contexte
Pour faire ces vérifications, l’approche classique consiste à définir un plan de stratégie de test (STP). A ce stade j’en imagine déjà certains en train de dire, pfff, des tests, de la doc, tout ca c’est ca a rien à voir avec le développement logiciel! Et bien ils se trompent car définir une stratégie de test est tout aussi important que d’avoir formalisé les besoins (auxquels les tests vont données des moyens de validation), d’avoir défini une architecture (qui sera aussi validé par les tests) où d’avoir un processus de développement (qui pourra s’appuyer sur les tests pour qualifier le logiciel et permettre son déroulement).
Ainsi le test est partout, dans tous les processus, à toutes les étapes, à tous les niveaux d’abstractions et il permet même de faciliter le développement en guidant le développeur en adoptant la démarche TDD (test driven development).
Dans cet article je vous propose dans un premier temps de revenir sur la définition d’un test puis de regarder les éléments faisant partie du plan de stratégie et d’identifier l’ensemble des types de tests qui peuvent être réalisés, leur objectifs et l’outillage éventuellement nécessaire pour les mettre en oeuvre.
Définition du test
Un test est une procédure permettant pour une assertion données de déclarer si celle ci est vrai ou fausse. Cette assertion est généralement la confrontation du résultat d’un calcul où d’une procédure comparé avec un résultat attendu.
La procédure permettant la mise en oeuvre d’un test consiste généralement à considérer l'élément à tester comme une noire de façon à ne pas préjuger de son implémentation et de ne se fier qu'à ses contrats d’interfaces (Par exemple pour une méthode, ce sont ses paramètres et retour, pour un composant, ce sont ses interfaces, pour un web service, le wsdl).
Enfin il reste à définir des scénarios d'exécution à l’aide de jeux de données d’entrées et de données attendues. A noter que si le composant a tester nécessite des dépendances, alors il convient de les déboucher avec des artefacts simulant le fonctionnement de celles-ci.
L'exécution des tests se doit alors de couvrir l’ensemble des fonctions attendues du composant,reproductible et constante dans le temps.
Test de recette
Tout d’abord et nous venons d’en parler, il a le test de recette. Ce test est un test permettant au client de valider la livraison sur un certain périmètre fonctionnel plus où moins grand selon les modifications apportées au logiciel dans la version.
C’est en toute logique l'équipe en charge du développement qui va proposer le protocole et le contenu du test de recette afin d’une part de permettre au client de le valider en amont de la livraison et également faciliter la reproductibilité de celui-ci. Ainsi sur des livraisons mineures et si la confiance est suffisante, ces tests pourront même être joué par l'équipe sur la base du protocole validé. Un compte rendu des tests sera ensuite livrés en même temps que le produit afin d’en attester des fonctionnalités. Le client aura alors toute la latitude de rejouer où non la version et les tests afin d’en vérifier les résultats prétendu obtenu par l'équipe.
Dans le plan de stratégie de test, le test de recette est évidemment indispensable et forcément majeur. Cependant, il n’est pas réaliste de croire que d’une part faire des tests pour la livraison est faisable surtout après plusieurs semaines de développement, et d’autre part que le client va s’en satisfaire.
Test du développement et de l’intégration continue
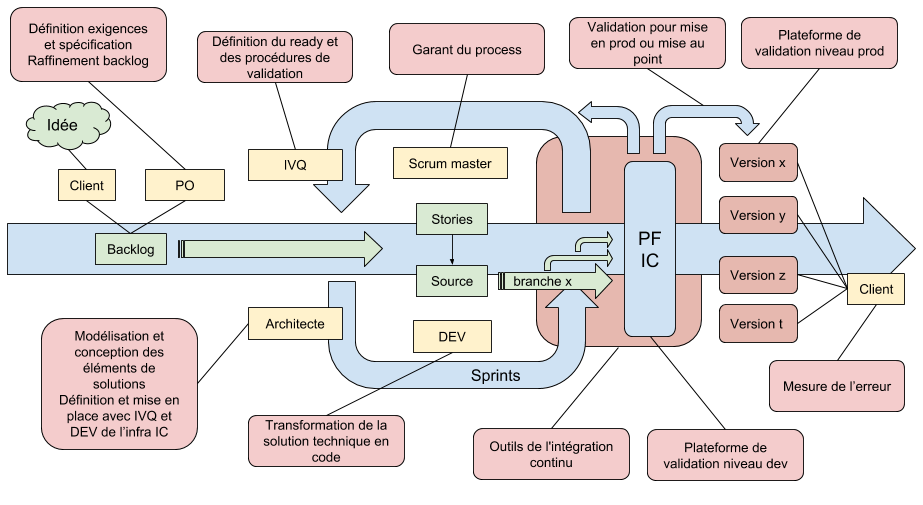
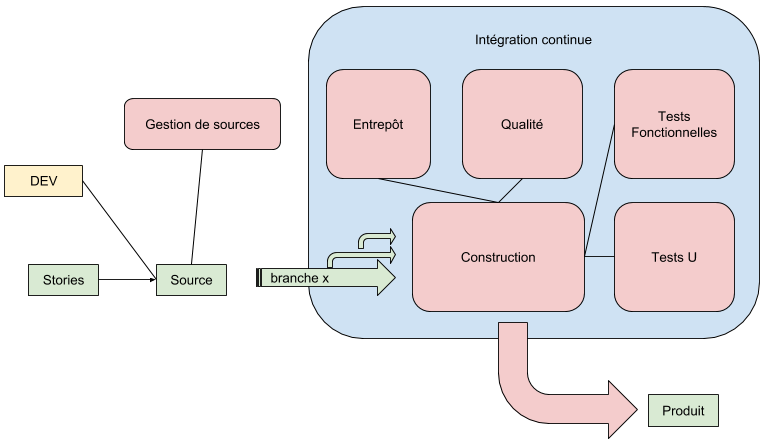
Pour répondre a ces problèmes, généralement, il est proposé de réaliser des tests en différents point du processus de développement et d’intégration du logiciel et ce de façon régulière (de préférence journalière). Cette approche qui nécessite souvent d'être automatisé (on peut même affirmer que c’est incontournable) permet l’identification au plus tôt des régressions éventuellement. Nous avions vu le principe de l'intégration continu dans l’article [1], il s’agit ici textuellement de la mise en oeuvre de cette partie du processus.
Différents types de tests pourront être distingué :
- Les tests unitaires
- Les test technique
- Les test d’interface
- Les test integration
- Les test de Base de données
- Les test d’IHM
- Les test fonctionnel
- Les test bout en bout
- Les test de qualimétrie
L’outil classique et le plus polyvalent pour répondre à la grande partie des mises en oeuvre des tests est indéniablement Robotframework [12]. Dédié le plus souvent aux tests fonctionnels, il permet de construire des DSL modélisant l’environnement des tests à réaliser permettant de l’adapter à tout type de test, que ce soit technique que fonctionnel.
Tests unitaires
En entré du processus d’IC, viennent les branches de développement. Ces branches sont issues du travaille des développeurs qui auront, selon les aspects techniques et les éléments fonctionnels impactés, ajoutés ou mis à jours les tests unitaires.
Les test unitaires sont des tests locaux sur les éléments du développement en cours dont le périmètre doit se restreindre au maximum aux briques essentielles de ce développement. Généralement les tests se limitent à la granularité minimal du code, en proposant un cadre exhaustif d'utilisation d’une méthode où plus largement d’une classe. Pour cela, de nombreux frameworks sont disponibles fournissant des primitives de tests facilitant la vérification de résultats attendus (le plus connu étant JUnit [2]) où fournissant des moyens de simplifications pour la mise en oeuvre des tests en facilitant soit la construction de jeux de données ou le bouchonnage de dépendances par la construction de Mock (soutenu par le framework Mockito [3] par exemple).
Les démarches de construction des tests unitaires sont variables. La pratique courante et que le développeur en charge de la réalisation d’une évolution se charge également de la réalisation du test. Ceci est considéré comme une mauvaise pratique pour deux raisons:
Tout d’abord, un test a pour but de démontrer une erreur dans la réalisation d’une fonction or généralement, les gens sont plutôt d’accord avec eux même. Il est vrai que parfois en écrivant le test, on se rend compte d’oubli mais le test n’est pas initialement le moment de comprendre le besoin, il ne sert qu'à démontrer le bon fonctionnement. On préconise donc que le test soit écrit par un autre développeur sachant que cela nécessite alors que les deux développeurs se mettent d’accord avec les interfaces du composant à tester/réaliser.
Second point, on préconise également pour faciliter la mise en oeuvre de la fonction que les tests soient défini préalablement afin de faciliter la compréhension de la fonction, la validation de celle-ci et d’avoir une mesure plus évidente de l’avancement. On appelle cette démarche le TDD (Test Driven Development)
De façon générale, les tests unitaires sont joués par le développeur lors du développement mais aussi lors de corrections dans l’objectif de contrôler la non régression technique où fonctionnel car même si les TU doivent être développé indépendamment, le code l’est rarement et parfois, avec des mocks, modifier une fonction et son test ne suffit pas pour garantir que tous les tests continueront à être valide. Ainsi de façon a ce que l'exécution des tests ne soient pas trop long il est indispensable de les faire simple et concis. Car il est évident que si l'exécution des tests prennent plus de 30 min à être exécuté par le développeur, ils auront à terme plus de chance de ne plus être exécuté….
Test technique
Le test technique est un test de haut niveau dont la portée n’est pas de garantir un besoin client mais la validation de où d’une partie de la solution technique. Ainsi un test technique ne cherche pas à garantir le but mais le moyen. Par exemple, on peut considérer que les TU sont une sorte de test technique, tout comme les tests sur des web services, d'intégration, de charge, de robustesse, de base de données d’IHM où encore de qualimétrie, etc…
Généralement si le processus de développement définit convenablement son référentiel documentaire et que celui ci s’appuie sur des exigences, alors le test technique permet la validation des exigences du cahier de conception (où d’architecture)
Test intégration
Les tests d'intégration sont des tests techniques primordiaux dans la vie de systèmes logiciels. On peut les considérer de deux sortes:
des tests d'intégration horizontaux qui traitent généralement des problématiques d'intégration propre aux choix d’architectures telles que les architectures modulaires et/ou réparti
des test verticaux traitant de la capacité de compatibilité des logiciels entre eux (par exemple, la capacité d’installation, configuration, désinstallation, mise a jours sur une où plusieurs type d’OS où dans des conteneurs d’applications différents)
Ces test sont souvent complexe à mener car difficile à automatiser et nécessitant une expertise transverse à l’ensemble des composants. De plus, les outils utilisables restent très spécifiques à chaque type d’interface à intégrer ainsi, il sera nécessaire de constituer des équipes conséquentes pour gérer une trop forte hétérogénéité surtout dans le cas de systèmes logiciels conséquent qui nécessitent souvent des plateformes d'intégrations dédiés
Test de Base de données
L’utilisation de base de données est incontournable dans les systèmes logiciels actuel. Il s’agit généralement d’un composant critique du système contenant toutes les informations relatives à l’exploitation du métier du client.
La vérification de base de données consiste généralement en la vérification des accès aux données, à la coherence d’insertion respectant les contraintes d'intégrités et que la suppression de données permet de conserver une base de données également intégrée et cohérente.
Pour faire ce genre de test, on pourra employer des outils facilitant la création, suppression et modification des données tels que Liquibase [4], dbdeploy [5] où JHipster [6].
Test d’IHM
Souvent considérés à tort comme des tests fonctionnels, les tests d’IHM sont en fait des tests techniques dont l’objet est la vérification d’ergonomie de l’application (qu’elle soit web où stand alone) et la présence effective des informations et contrôleurs permettant les interactions du client.
La confusion entre test fonctionnel et test ihm est simple, elle provient de la simplification de la stratégie de vérification en proposant dans une plateforme d'intégration (donc relativement complète techniquement) des procédures déroulant les cas d’utilisation du client. Ces procédures (généralement réalisées manuellement et considérées comme des tests fonctionnels) sont en fait des tests de recette permettant une couverture non-exhaustive des fonctionnalités. S'ils permettent d’avoir un bon apriori sur le périmètre fonctionnel viable il n’en donne pas une information réelle. De même nous verrons dans un chapitre suivant qu'à l’inverse un test fonctionnel n’est pas forcément un test d’IHM.
La mise en oeuvre de test d’IHM est complexe car la boite noire a tester est l’IHM dans son environnement d'exécution. Ainsi le point d’entrée d’une IHM est généralement un écran, un clavier et une souris et donc s’assimile souvent à des images corrélées à des événements claviers/souris ainsi que la position de cette dernière.
Pour répondre à ce genre de problématiques, il existe deux approches:
La première consiste a considérer l'écran tel quel le voit l’utilisateur et d’enregistrer les actions utilisateurs et déplacement souris. Ainsi, suite a l’enregistrement il sera possible de rejouer le test. Cette approche est proposé par des outils comme Selenium [7] et Sikuli [8]. Bien que peu robuste aux modifications même infime d’IHM, ces approches sont difficiles à maintenir.
La seconde approche consiste à utiliser des outils d’introspection capable d’identifier les composants de l’IHM pendant leur exécution et de simuler les actions d’un utilisateur. Dans cette approche, l’avantage est clairement la simplification des tests qui alors devient des tests classiques presque unitaire. Cependant, tous les framework d’IHM ne permettent cette approche car si en Java Swing, il sera facile d’utiliser Fest [9], dès que l’on utilisera une IHM Web, il sera nécessaire de se rabattre sur des tests utilisant l’approche précédente.
Test de qualimétrie
Les tests de qualimétrie sont des tests technique portant sur la qualité du logiciel en terme de vulnérabilité, maintenabilité, bug potentiel, couverture de test et duplication de code. Ces informations sont élaborées par des outils exploitant les phases de compilations, de test unitaire où de tests spécifiques. Ainsi dans ce contexte le plus connu est probablement aujourd’hui Sonar [10] qui permet la consolidation de ces différents critères.
A noter quand dans la pratique, ces informations sont trop souvent négligé à tort car les configurations par défaut s'appuient sur les recommandations construites par les communautés et fournissent un cadre formatif très poussé pour comprendre beaucoup de subtilités des langages traités
Test de charge
Les tests de charges sont des tests techniques où l’application est mise en situation de fonctionnement nominal avec des fluctuations sur les débits des flux entrant.
Le but de ce type de test est de visualiser le comportement du système dans les cas normaux et également aux limites, lorsque celui-ci est sollicité de façon exagérée. On procédera souvent a des mesure de temps de traversé des données et des temps de réponse du composant pour la prise en compte des sollicitations.
Ces tests ne sont pas souvent mise en oeuvre car étant coûteux à mettre en oeuvre même si des outils existent comme JMeter [11]
Test de robustesse
Le test de robustesse, comme le test de charge est un type de test technique où le but est la mise en situation critique du logiciel soit sur des cas d’utilisation non prévu, soit dans les cas de défaillances pendant lesquels, le logiciel doit être en mesure soit de continuer à assurer le service soit au mieux permettre aux services parallèles de continuer à fonctionner. Les tests de robustesses sont à définir sur de nombreux plans, des TU aux tests d’IHM, aux tests de base de données où même de charge.
Le cas typique du test de robustesse est la résistance à des données d’entrée corrompu susceptible de corrompre le fonctionnement.
Test fonctionnel
Souvent confondu avec les tests d’IHM comme nous en avons parlé précédemment, les tests fonctionnels sont défini sur la base de la définition du besoin du client. Ils permettent de vérifier la faisabilité et la cohérence fonctionnelle du besoin en formalisant et scénarisant son utilisation. Ainsi le test fonctionnel (et ses UC) sert de référentiel pour la couverture complète du besoin et est généralement la base pour la constitution des tests de recettes qui en forme souvent un sous ensemble lorsque ces derniers traitent des IHM.
Test bout en bout
Lest test bout en bout regroupent l’ensemble des tests permettant la traversé complète du système logiciel, du point d’entré jusqu’aux bases de données en incluant les retours de données éventuels. Selon le test, cela ne signifie pas forcément la même chose, il est évident que toutes les fonctions ne réalisent pas les mêmes trajets, mais c’est l'intérêt de ces tests finalement: fournir une couverture exhaustive de l’ensemble des traversés possibles du système.
Dans ce genre de test, l’utilisation d’outils comme Robotframework est indispensable en permettant de construire des DSL spécifique a chaque type de test bout en bout rencontré. Cela nécessitera cependant la création de bouchons afin donner l’impression que les systèmes externes sont opérant.
Conclusion
Voilà nous arrivons au bout de ce long article sur les tests. Ils sont souvent complexe à réaliser et s’appliquent sur divers aspects du système logiciel, a tous les niveaux d’abstraction et selon des méthodes et des approches variés. Pourtant même les tests ne sont pas forcément à la hauteur du système logiciel qu’ils doivent validé, Ils sont indispensables à la qualité du produit et à la confiance que le client pourra donner au système logiciel. Ainsi, il n’est jamais bon de négliger les tests
Références
[1] http://un-est-tout-et-tout-est-un.blogspot.fr/2018/02/integration-continue.html
[2] https://junit.org/junit5/
[3] http://site.mockito.org/
[4] https://www.liquibase.org/
[5] http://dbdeploy.com/
[6] https://www.jhipster.tech/
[7] https://www.seleniumhq.org/
[8] http://www.sikuli.org/
[9] https://un-est-tout-et-tout-est-un.blogspot.fr/2018/01/test-dihm-fest-util.html
[10] https://about.sonarcloud.io/
[11] https://jmeter.apache.org/
[12] http://robotframework.org/