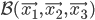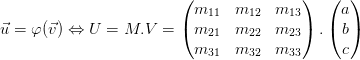Ainsi, au fils des articles nous avons croisé un certain nombre de patterns ou de framework qui clairement nous simplifie la vie pour produire notre application. Cependant ce genre de concepts se focalisent exclusivement sur le logiciel lui même sans fournir de réponses à des besoins environnementaux qui peuvent être nombreux et contraignants
Ainsi par exemple, que faire lorsque le logiciel doit être capable de gérer un taux de connexion élevé? Comment garantir la monté en charge? Comment s’assurer de l'intégrité des données ? de leur disponibilités ? de leur sauvegarde? Comment garantir qu’il n’y aura pas d'interruption de service? A toutes ces questions, le logiciel seul ne peut y répondre en plus du besoin pour lequel il est produit. En effet, si techniquement on peut imaginer répondre à ces problématiques, cela nécessiterait des développement spécifiques très lourd en plus du métier pour lequel le logiciel doit être fait et comme nous l’avons vu précédemment, toutes les approches purement logiciel sont beaucoup trop auto-centré.
A cette problématique existe heureusement un solution et celle-ci relève en fait du bon sens. Ainsi, si un logiciel doit être conçu et architecturé, son environnement doit l'être aussi! Et les choix d’architectures (interne et externe au logiciel) doivent permettre à ces deux systèmes de cohabiter.
Nous allons donc prendre un peu de recul sur la conception logiciel elle même et nous placer au dessus des patterns de conception que nous avons vu jusque ici pour regarder le logiciel de façon plus global. L’objectif est toujours de considérer le logiciel avec ses interfaces mais aussi de regarder au delà de celles ci pour penser l’architecture dans son ensemble.
Reprenons pour commencer l’exemple très simple de notre article sur le DAO [1]. Nous avions vu l’une des architectures les plus typiques, l’architecture en 3 couches permettant de dissocier les préoccupations métiers des préoccupations de représentations (la couche presentation) des préoccupations de stockage (la couches de données).



Pour répondre à cette problématique, heureusement il existe également des solutions. Le problème de l’architecture en couche est d'être vertical. Ainsi, une solution est de fournir des fonctionnalités transverses déployées de manière horizontale.
De façon à concevoir des architectures plus horizontale, une approche dite orientée service est possible ou SOA [7]. Celle ci est apparue peu avant 2000 et a largement bénéficié de l'émergence des webservices. Le principe de SOA est simple, il se base sur le principe du producteur consommateur avec comme produit le service.

Pour orchestrer ces communications [8], un annuaire (UDDI) permet la définition d’un référentiel des services accessibles sur un bus de communication servant de middleware (souvent un ESB mais pouvant reposer plus simplement sur le Web si la sécurisation est complètement pris en compte). Enfin tous ces éléments vont reposer sur le standard xml pour faciliter l'interopérabilité de la communication et l'échange des données en restant conforme aux contrats définis pour les services en exploitant des support de communication comme SOAP ou JMS.
L'intérêt de ce genre d’architecture est clairement la mise en place d’un découplage entre les fonctions fourni par les services permettant à des équipes différentes de les développer indépendamment, sur des cibles potentiellement hétérogènes (OS, frameworks, language). de plus cela permet de faire vivre dans le même environnement des applications requièrant les même services ou partiellement. De même faire évoluer ce type de système se résume alors à l’identification des services à exploiter et des nouveaux à déployer.
La réside la difficulté de cette approche. Il faut être capable de dimensionner correctement les services de façon à ce qu’ils soient ni trop simple au risque d'être trop exploité avec des risques notable de perte de performances (à noter qu’un service est censé être unique donc c’est à lui de gérer l’exploitation de la demande et la monté en charge) soit trop complexe et donc trop peu réutilisable. Les architectures orienté service sont donc souvent confronté aux problèmes de performances qui sont directement relié aux capacités réseaux et aux capacités en temps de réponse des plus fragiles des services du système ( qui peuvent en ralentir ou d'encombrer drastiquement le fonctionnement) A noter que ce n’est pas le seul point noir car, si ls SOA favorise la modularité et le reuse des services, cela ne favorise pas son evoluabilité. Toutes transformations dans la chaîne des processus EBP (Enterprise Business Process) utilisant les services entraînera de forte perturbation sur l’ESB.
Pour palier à ces défauts les microservices proposent de descendre encore en granularité dans la décomposition fonctionnelle. Ainsi un microservice va se réduire à ne répondre qu'à une et une unique fonction tout en simplifiant les protocoles de communication par l’utilisation de REST par exemple et en supprimant le principe de bus. L’idée principale est de produire une fournir un plus grand nombre de services (en comparaison à SOA) mais plus simple, élémentaire et donc plus indépendant. Cela va alors faciliter leur maintenance et leur interchangeabilité.

Jusque là nous nous sommes projetés dans des architectures sans parler de la structure réseau sous-jacente. Bien sur aujourd’hui une application ne se pense plus de façon stand alone sur un serveur, elles se pensent embarquées dans un ou plusieurs serveurs d’applications répartis sur plusieurs serveurs physiques et les approches de types SOA ou Microservices se prêtent parfaitement à cela mais si l’on ne considère pas forcément ce type de solutions, pourquoi malgré tout choisir une architecture distribuée et/ou décentralisé?
En réalité la réponse est simple, et c’est toujours la même, une architecture bien pensé doit permettre d'éviter de construire des monolithes immaintenables (remarque, si ca nous fait évoluer...) et la décomposition est souvent la première des bonnes idées à avoir.
Nous avons vu que ces principes font parti intégrante des architectures précédentes. En fait si les architectures distribuées et/ou décentralisées sont intéressantes c’est parce que non seulement elle poussent à décomposer le problème et favoriser ainsi la réutilisabilité, la maintenabilité (le problème étant localement plus simple du coup) mais elles permettent aussi d'intégrer des solutions techniques répondant à des problèmes plus spécifiques et techniques exigés par le client comme des exigences de disponibilités, de montées en charges, de vitesse de traitement, etc...

source: Architecture fédérée
Par contre, il ne faut pas croire que parce que l’on va considérer une architecture distribuée et ou décentralisé, les problèmes sont terminées car cela peut aussi être une fausse bonne idées dans certains cas. En effet, souvent ce genre d'architecture nécessite d'incorporer au mieux des outils spécifiques permettant la gestion du problème considéré mais selon les cas, il faudra penser à des mécanismes spécifiquement développées par l'équipe de développement. Dans ce genre de cas, on s’engage souvent sur un chemin complexe car ce genre d'architecture ne sont pas simple à gérer soit même. Par exemple, si nous considérons le cas d’une architecture orienté données qu’est l’architecture fédérée, elle a pour objet de permettre la mise en collaboration de différentes bases de données pour donner l’illusion qu’elle n’en forme qu’une tout en leur permettant de rester indépendantes. Si l’idée est pertinente, dans la pratique (dans le cas de fédérations faiblement couplé), elle nécessite de constituer des vue spécifiques dans chacunes des bases, des schémas supplémentaires (privé : base initiale , export : données présenté aux autres bases, import : données reconstitué des autres base) et des mécanismes de reconstruction. Ce genre d’approche est très complexe à mener et doit être refait pour à chaque intégration d’une nouvelle base dans la fédération. Il sera probablement plus simple de réaliser une migration des données vers des bases repensées plus globalement.

Alors bien sur le cas des architectures fédérées n’est pas à généraliser et elle peuvent aussi trouver leur applications dans certains cas bien étudié. Il ne faut pas oblitérer que ce genre d’architecture permettent aussi de gérer des problématiques de redondances ou de répartition de charge pour obtenir des services en haute disponibilité.
Pour conclure cet article déjà assez long, on statuera sur le fait que toutes les architectures décrites jusqu'ici sont plutôt classiques alors aujourd’hui, de nouvelles architectures font leur apparition pour intégrer de nouveaux types de besoins comme l'intégration de service dans le cloud, le traitement de données massives, le besoin de procéder à des prévisions ou des profils de ventes grâce à du Big Data ou du Machine learning. Nous ne rentrerons pas dans le détails de celles ci maintenant mais nous y reviendrons.
Références:
[1] https://un-est-tout-et-tout-est-un.blogspot.fr/2018/03/design-pattern-dao.html[2] https://un-est-tout-et-tout-est-un.blogspot.fr/2017/10/la-conception-logicielle.html
[3] https://un-est-tout-et-tout-est-un.blogspot.fr/2017/12/la-modelisation.html
[4] https://un-est-tout-et-tout-est-un.blogspot.fr/p/java.html
[5] https://jobprod.com/quelques-principes-darchitecture-dapplis-web-javajee/
[6] https://dzone.com/articles/microservices-vs-soa-is-there-any-difference-at-al
[7] https://www.piloter.org/techno/support/SOA.htm
[8] https://openclassrooms.com/courses/implementez-une-architecture-orientee-services-soa-en-java/mprendrecequecestunesoa